|
|
| (16 dazwischenliegende Versionen von 2 Benutzern werden nicht angezeigt) |
| Zeile 1: |
Zeile 1: |
| =Prozesskontrollblock unter Linux=
| | Das folgende Videos zeigt, wie man in den Quelltexten des Linux-Kernels die Deklaration des Linux-Prozesskontrollblocks (''task_struct'') findet, und wie der Zusammenhang mit der Prozesstabelle ist. |
| | </p> |
|
| |
|
| <br />
| |
| == Beispiel: Prozesskontrollblock unter Linux ==
| |
| <p> | | <p> |
| <loop_area type="notice">'''Weiterführende Literatur''' | | <loop_area icon="Video.png" icontext="Video"> |
| <p> | | <loop_media type="video" title="Prozesskontrollblock im Linux-Quellcode" description="http://youtu.be/QeerwZOO9bw" copyright="CC-BY" index=true show_copyright=true id="5fa97870a702d"> |
| <cite>Achilles+2006</cite> zeigt in Kapitel 3.1 den ''Linux Process Control Block''. Die Lektüre dieser Quelle sei ausdrücklich empfohlen. | | {{#ev:youtube|QeerwZOO9bw|700}} |
| | </loop_media> |
| | </loop_area> |
| </p> | | </p> |
| | |
| | <br /> |
| | == task_struct: Deklaration des Linux-Prozesskontrollblocks == |
| <p> | | <p> |
| <small>
| | Der folgende Auszug aus der Quelltext-Datei ''sched.h'' des Linux-Kernels (Version 3.13.0) zeigt die Deklaration der Datenstruktur ''task_struct''. Dabei handelt es sich um den Prozesskontrollblock, wie er von Linux verwendet wird. |
| Studierende sind oftmals berechtigt, eine PDF-Version dieses Buches ohne entstehende Kosten [[Hinweise für Studierende#Downloadbare Bücher von Springerlink|über ihre Hochschulen von Springerlink zu beziehen.]]
| |
| </small>
| |
| </p> | | </p> |
| </loop_area>
| |
| </p>
| |
|
| |
| ==== sched.h ====
| |
| <br /> | | <br /> |
| <p> | | <p> |
| <loop_listing title="Quelltext der Datei sched.h aus dem Linux-Kernel" description="Der Prozesskontrollblock ist deklariert zwischen Zeile 1043 und 1459.">
| | <source lang="c" line="true"> |
| <source lang="c++" line="true"> | |
| #ifndef _LINUX_SCHED_H
| |
| #define _LINUX_SCHED_H
| |
| | |
| #include <uapi/linux/sched.h>
| |
| | |
| | |
| struct sched_param {
| |
| int sched_priority;
| |
| };
| |
| | |
| #include <asm/param.h> /* for HZ */
| |
| | |
| #include <linux/capability.h>
| |
| #include <linux/threads.h>
| |
| #include <linux/kernel.h>
| |
| #include <linux/types.h>
| |
| #include <linux/timex.h>
| |
| #include <linux/jiffies.h>
| |
| #include <linux/rbtree.h>
| |
| #include <linux/thread_info.h>
| |
| #include <linux/cpumask.h>
| |
| #include <linux/errno.h>
| |
| #include <linux/nodemask.h>
| |
| #include <linux/mm_types.h>
| |
| #include <linux/preempt_mask.h>
| |
| | |
| #include <asm/page.h>
| |
| #include <asm/ptrace.h>
| |
| #include <asm/cputime.h>
| |
| | |
| #include <linux/smp.h>
| |
| #include <linux/sem.h>
| |
| #include <linux/signal.h>
| |
| #include <linux/compiler.h>
| |
| #include <linux/completion.h>
| |
| #include <linux/pid.h>
| |
| #include <linux/percpu.h>
| |
| #include <linux/topology.h>
| |
| #include <linux/proportions.h>
| |
| #include <linux/seccomp.h>
| |
| #include <linux/rcupdate.h>
| |
| #include <linux/rculist.h>
| |
| #include <linux/rtmutex.h>
| |
| | |
| #include <linux/time.h>
| |
| #include <linux/param.h>
| |
| #include <linux/resource.h>
| |
| #include <linux/timer.h>
| |
| #include <linux/hrtimer.h>
| |
| #include <linux/task_io_accounting.h>
| |
| #include <linux/latencytop.h>
| |
| #include <linux/cred.h>
| |
| #include <linux/llist.h>
| |
| #include <linux/uidgid.h>
| |
| #include <linux/gfp.h>
| |
| | |
| #include <asm/processor.h>
| |
| | |
| struct exec_domain;
| |
| struct futex_pi_state;
| |
| struct robust_list_head;
| |
| struct bio_list;
| |
| struct fs_struct;
| |
| struct perf_event_context;
| |
| struct blk_plug;
| |
| | |
| /*
| |
| * List of flags we want to share for kernel threads,
| |
| * if only because they are not used by them anyway.
| |
| */
| |
| #define CLONE_KERNEL (CLONE_FS | CLONE_FILES | CLONE_SIGHAND)
| |
| | |
| /*
| |
| * These are the constant used to fake the fixed-point load-average
| |
| * counting. Some notes:
| |
| * - 11 bit fractions expand to 22 bits by the multiplies: this gives
| |
| * a load-average precision of 10 bits integer + 11 bits fractional
| |
| * - if you want to count load-averages more often, you need more
| |
| * precision, or rounding will get you. With 2-second counting freq,
| |
| * the EXP_n values would be 1981, 2034 and 2043 if still using only
| |
| * 11 bit fractions.
| |
| */
| |
| extern unsigned long avenrun[]; /* Load averages */
| |
| extern void get_avenrun(unsigned long *loads, unsigned long offset, int shift);
| |
| | |
| #define FSHIFT 11 /* nr of bits of precision */
| |
| #define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point */
| |
| #define LOAD_FREQ (5*HZ+1) /* 5 sec intervals */
| |
| #define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
| |
| #define EXP_5 2014 /* 1/exp(5sec/5min) */
| |
| #define EXP_15 2037 /* 1/exp(5sec/15min) */
| |
| | |
| #define CALC_LOAD(load,exp,n) \
| |
| load *= exp; \
| |
| load += n*(FIXED_1-exp); \
| |
| load >>= FSHIFT;
| |
| | |
| extern unsigned long total_forks;
| |
| extern int nr_threads;
| |
| DECLARE_PER_CPU(unsigned long, process_counts);
| |
| extern int nr_processes(void);
| |
| extern unsigned long nr_running(void);
| |
| extern unsigned long nr_iowait(void);
| |
| extern unsigned long nr_iowait_cpu(int cpu);
| |
| extern unsigned long this_cpu_load(void);
| |
| | |
| | |
| extern void calc_global_load(unsigned long ticks);
| |
| extern void update_cpu_load_nohz(void);
| |
| | |
| extern unsigned long get_parent_ip(unsigned long addr);
| |
| | |
| extern void dump_cpu_task(int cpu);
| |
| | |
| struct seq_file;
| |
| struct cfs_rq;
| |
| struct task_group;
| |
| #ifdef CONFIG_SCHED_DEBUG
| |
| extern void proc_sched_show_task(struct task_struct *p, struct seq_file *m);
| |
| extern void proc_sched_set_task(struct task_struct *p);
| |
| extern void
| |
| print_cfs_rq(struct seq_file *m, int cpu, struct cfs_rq *cfs_rq);
| |
| #endif
| |
| | |
| /*
| |
| * Task state bitmask. NOTE! These bits are also
| |
| * encoded in fs/proc/array.c: get_task_state().
| |
| *
| |
| * We have two separate sets of flags: task->state
| |
| * is about runnability, while task->exit_state are
| |
| * about the task exiting. Confusing, but this way
| |
| * modifying one set can't modify the other one by
| |
| * mistake.
| |
| */
| |
| #define TASK_RUNNING 0
| |
| #define TASK_INTERRUPTIBLE 1
| |
| #define TASK_UNINTERRUPTIBLE 2
| |
| #define __TASK_STOPPED 4
| |
| #define __TASK_TRACED 8
| |
| /* in tsk->exit_state */
| |
| #define EXIT_ZOMBIE 16
| |
| #define EXIT_DEAD 32
| |
| /* in tsk->state again */
| |
| #define TASK_DEAD 64
| |
| #define TASK_WAKEKILL 128
| |
| #define TASK_WAKING 256
| |
| #define TASK_PARKED 512
| |
| #define TASK_STATE_MAX 1024
| |
| | |
| #define TASK_STATE_TO_CHAR_STR "RSDTtZXxKWP"
| |
| | |
| extern char ___assert_task_state[1 - 2*!!(
| |
| sizeof(TASK_STATE_TO_CHAR_STR)-1 != ilog2(TASK_STATE_MAX)+1)];
| |
| | |
| /* Convenience macros for the sake of set_task_state */
| |
| #define TASK_KILLABLE (TASK_WAKEKILL | TASK_UNINTERRUPTIBLE)
| |
| #define TASK_STOPPED (TASK_WAKEKILL | __TASK_STOPPED)
| |
| #define TASK_TRACED (TASK_WAKEKILL | __TASK_TRACED)
| |
| | |
| /* Convenience macros for the sake of wake_up */
| |
| #define TASK_NORMAL (TASK_INTERRUPTIBLE | TASK_UNINTERRUPTIBLE)
| |
| #define TASK_ALL (TASK_NORMAL | __TASK_STOPPED | __TASK_TRACED)
| |
| | |
| /* get_task_state() */
| |
| #define TASK_REPORT (TASK_RUNNING | TASK_INTERRUPTIBLE | \
| |
| TASK_UNINTERRUPTIBLE | __TASK_STOPPED | \
| |
| __TASK_TRACED)
| |
| | |
| #define task_is_traced(task) ((task->state & __TASK_TRACED) != 0)
| |
| #define task_is_stopped(task) ((task->state & __TASK_STOPPED) != 0)
| |
| #define task_is_dead(task) ((task)->exit_state != 0)
| |
| #define task_is_stopped_or_traced(task) \
| |
| ((task->state & (__TASK_STOPPED | __TASK_TRACED)) != 0)
| |
| #define task_contributes_to_load(task) \
| |
| ((task->state & TASK_UNINTERRUPTIBLE) != 0 && \
| |
| (task->flags & PF_FROZEN) == 0)
| |
| | |
| #define __set_task_state(tsk, state_value) \
| |
| do { (tsk)->state = (state_value); } while (0)
| |
| #define set_task_state(tsk, state_value) \
| |
| set_mb((tsk)->state, (state_value))
| |
| | |
| /*
| |
| * set_current_state() includes a barrier so that the write of current->state
| |
| * is correctly serialised wrt the caller's subsequent test of whether to
| |
| * actually sleep:
| |
| *
| |
| * set_current_state(TASK_UNINTERRUPTIBLE);
| |
| * if (do_i_need_to_sleep())
| |
| * schedule();
| |
| *
| |
| * If the caller does not need such serialisation then use __set_current_state()
| |
| */
| |
| #define __set_current_state(state_value) \
| |
| do { current->state = (state_value); } while (0)
| |
| #define set_current_state(state_value) \
| |
| set_mb(current->state, (state_value))
| |
| | |
| /* Task command name length */
| |
| #define TASK_COMM_LEN 16
| |
| | |
| #include <linux/spinlock.h>
| |
| | |
| /*
| |
| * This serializes "schedule()" and also protects
| |
| * the run-queue from deletions/modifications (but
| |
| * _adding_ to the beginning of the run-queue has
| |
| * a separate lock).
| |
| */
| |
| extern rwlock_t tasklist_lock;
| |
| extern spinlock_t mmlist_lock;
| |
| | |
| struct task_struct;
| |
| | |
| #ifdef CONFIG_PROVE_RCU
| |
| extern int lockdep_tasklist_lock_is_held(void);
| |
| #endif /* #ifdef CONFIG_PROVE_RCU */
| |
| | |
| extern void sched_init(void);
| |
| extern void sched_init_smp(void);
| |
| extern asmlinkage void schedule_tail(struct task_struct *prev);
| |
| extern void init_idle(struct task_struct *idle, int cpu);
| |
| extern void init_idle_bootup_task(struct task_struct *idle);
| |
| | |
| extern int runqueue_is_locked(int cpu);
| |
| | |
| #if defined(CONFIG_SMP) && defined(CONFIG_NO_HZ_COMMON)
| |
| extern void nohz_balance_enter_idle(int cpu);
| |
| extern void set_cpu_sd_state_idle(void);
| |
| extern int get_nohz_timer_target(void);
| |
| #else
| |
| static inline void nohz_balance_enter_idle(int cpu) { }
| |
| static inline void set_cpu_sd_state_idle(void) { }
| |
| #endif
| |
| | |
| /*
| |
| * Only dump TASK_* tasks. (0 for all tasks)
| |
| */
| |
| extern void show_state_filter(unsigned long state_filter);
| |
| | |
| static inline void show_state(void)
| |
| {
| |
| show_state_filter(0);
| |
| }
| |
| | |
| extern void show_regs(struct pt_regs *);
| |
| | |
| /*
| |
| * TASK is a pointer to the task whose backtrace we want to see (or NULL for current
| |
| * task), SP is the stack pointer of the first frame that should be shown in the back
| |
| * trace (or NULL if the entire call-chain of the task should be shown).
| |
| */
| |
| extern void show_stack(struct task_struct *task, unsigned long *sp);
| |
| | |
| void io_schedule(void);
| |
| long io_schedule_timeout(long timeout);
| |
| | |
| extern void cpu_init (void);
| |
| extern void trap_init(void);
| |
| extern void update_process_times(int user);
| |
| extern void scheduler_tick(void);
| |
| | |
| extern void sched_show_task(struct task_struct *p);
| |
| | |
| #ifdef CONFIG_LOCKUP_DETECTOR
| |
| extern void touch_softlockup_watchdog(void);
| |
| extern void touch_softlockup_watchdog_sync(void);
| |
| extern void touch_all_softlockup_watchdogs(void);
| |
| extern int proc_dowatchdog_thresh(struct ctl_table *table, int write,
| |
| void __user *buffer,
| |
| size_t *lenp, loff_t *ppos);
| |
| extern unsigned int softlockup_panic;
| |
| void lockup_detector_init(void);
| |
| #else
| |
| static inline void touch_softlockup_watchdog(void)
| |
| {
| |
| }
| |
| static inline void touch_softlockup_watchdog_sync(void)
| |
| {
| |
| }
| |
| static inline void touch_all_softlockup_watchdogs(void)
| |
| {
| |
| }
| |
| static inline void lockup_detector_init(void)
| |
| {
| |
| }
| |
| #endif
| |
| | |
| #ifdef CONFIG_DETECT_HUNG_TASK
| |
| void reset_hung_task_detector(void);
| |
| #else
| |
| static inline void reset_hung_task_detector(void)
| |
| {
| |
| }
| |
| #endif
| |
| | |
| /* Attach to any functions which should be ignored in wchan output. */
| |
| #define __sched __attribute__((__section__(".sched.text")))
| |
| | |
| /* Linker adds these: start and end of __sched functions */
| |
| extern char __sched_text_start[], __sched_text_end[];
| |
| | |
| /* Is this address in the __sched functions? */
| |
| extern int in_sched_functions(unsigned long addr);
| |
| | |
| #define MAX_SCHEDULE_TIMEOUT LONG_MAX
| |
| extern signed long schedule_timeout(signed long timeout);
| |
| extern signed long schedule_timeout_interruptible(signed long timeout);
| |
| extern signed long schedule_timeout_killable(signed long timeout);
| |
| extern signed long schedule_timeout_uninterruptible(signed long timeout);
| |
| asmlinkage void schedule(void);
| |
| extern void schedule_preempt_disabled(void);
| |
| | |
| struct nsproxy;
| |
| struct user_namespace;
| |
| | |
| #ifdef CONFIG_MMU
| |
| extern void arch_pick_mmap_layout(struct mm_struct *mm);
| |
| extern unsigned long
| |
| arch_get_unmapped_area(struct file *, unsigned long, unsigned long,
| |
| unsigned long, unsigned long);
| |
| extern unsigned long
| |
| arch_get_unmapped_area_topdown(struct file *filp, unsigned long addr,
| |
| unsigned long len, unsigned long pgoff,
| |
| unsigned long flags);
| |
| #else
| |
| static inline void arch_pick_mmap_layout(struct mm_struct *mm) {}
| |
| #endif
| |
| | |
| | |
| extern void set_dumpable(struct mm_struct *mm, int value);
| |
| extern int get_dumpable(struct mm_struct *mm);
| |
| | |
| #define SUID_DUMP_DISABLE 0 /* No setuid dumping */
| |
| #define SUID_DUMP_USER 1 /* Dump as user of process */
| |
| #define SUID_DUMP_ROOT 2 /* Dump as root */
| |
| | |
| /* mm flags */
| |
| /* dumpable bits */
| |
| #define MMF_DUMPABLE 0 /* core dump is permitted */
| |
| #define MMF_DUMP_SECURELY 1 /* core file is readable only by root */
| |
| | |
| #define MMF_DUMPABLE_BITS 2
| |
| #define MMF_DUMPABLE_MASK ((1 << MMF_DUMPABLE_BITS) - 1)
| |
| | |
| /* coredump filter bits */
| |
| #define MMF_DUMP_ANON_PRIVATE 2
| |
| #define MMF_DUMP_ANON_SHARED 3
| |
| #define MMF_DUMP_MAPPED_PRIVATE 4
| |
| #define MMF_DUMP_MAPPED_SHARED 5
| |
| #define MMF_DUMP_ELF_HEADERS 6
| |
| #define MMF_DUMP_HUGETLB_PRIVATE 7
| |
| #define MMF_DUMP_HUGETLB_SHARED 8
| |
| | |
| #define MMF_DUMP_FILTER_SHIFT MMF_DUMPABLE_BITS
| |
| #define MMF_DUMP_FILTER_BITS 7
| |
| #define MMF_DUMP_FILTER_MASK \
| |
| (((1 << MMF_DUMP_FILTER_BITS) - 1) << MMF_DUMP_FILTER_SHIFT)
| |
| #define MMF_DUMP_FILTER_DEFAULT \
| |
| ((1 << MMF_DUMP_ANON_PRIVATE) | (1 << MMF_DUMP_ANON_SHARED) |\
| |
| (1 << MMF_DUMP_HUGETLB_PRIVATE) | MMF_DUMP_MASK_DEFAULT_ELF)
| |
| | |
| #ifdef CONFIG_CORE_DUMP_DEFAULT_ELF_HEADERS
| |
| # define MMF_DUMP_MASK_DEFAULT_ELF (1 << MMF_DUMP_ELF_HEADERS)
| |
| #else
| |
| # define MMF_DUMP_MASK_DEFAULT_ELF 0
| |
| #endif
| |
| /* leave room for more dump flags */
| |
| #define MMF_VM_MERGEABLE 16 /* KSM may merge identical pages */
| |
| #define MMF_VM_HUGEPAGE 17 /* set when VM_HUGEPAGE is set on vma */
| |
| #define MMF_EXE_FILE_CHANGED 18 /* see prctl_set_mm_exe_file() */
| |
| | |
| #define MMF_HAS_UPROBES 19 /* has uprobes */
| |
| #define MMF_RECALC_UPROBES 20 /* MMF_HAS_UPROBES can be wrong */
| |
| | |
| #define MMF_INIT_MASK (MMF_DUMPABLE_MASK | MMF_DUMP_FILTER_MASK)
| |
| | |
| struct sighand_struct {
| |
| atomic_t count;
| |
| struct k_sigaction action[_NSIG];
| |
| spinlock_t siglock;
| |
| wait_queue_head_t signalfd_wqh;
| |
| };
| |
| | |
| struct pacct_struct {
| |
| int ac_flag;
| |
| long ac_exitcode;
| |
| unsigned long ac_mem;
| |
| cputime_t ac_utime, ac_stime;
| |
| unsigned long ac_minflt, ac_majflt;
| |
| };
| |
| | |
| struct cpu_itimer {
| |
| cputime_t expires;
| |
| cputime_t incr;
| |
| u32 error;
| |
| u32 incr_error;
| |
| };
| |
| | |
| /**
| |
| * struct cputime - snaphsot of system and user cputime
| |
| * @utime: time spent in user mode
| |
| * @stime: time spent in system mode
| |
| *
| |
| * Gathers a generic snapshot of user and system time.
| |
| */
| |
| struct cputime {
| |
| cputime_t utime;
| |
| cputime_t stime;
| |
| };
| |
| | |
| /**
| |
| * struct task_cputime - collected CPU time counts
| |
| * @utime: time spent in user mode, in &cputime_t units
| |
| * @stime: time spent in kernel mode, in &cputime_t units
| |
| * @sum_exec_runtime: total time spent on the CPU, in nanoseconds
| |
| *
| |
| * This is an extension of struct cputime that includes the total runtime
| |
| * spent by the task from the scheduler point of view.
| |
| *
| |
| * As a result, this structure groups together three kinds of CPU time
| |
| * that are tracked for threads and thread groups. Most things considering
| |
| * CPU time want to group these counts together and treat all three
| |
| * of them in parallel.
| |
| */
| |
| struct task_cputime {
| |
| cputime_t utime;
| |
| cputime_t stime;
| |
| unsigned long long sum_exec_runtime;
| |
| };
| |
| /* Alternate field names when used to cache expirations. */
| |
| #define prof_exp stime
| |
| #define virt_exp utime
| |
| #define sched_exp sum_exec_runtime
| |
| | |
| #define INIT_CPUTIME \
| |
| (struct task_cputime) { \
| |
| .utime = 0, \
| |
| .stime = 0, \
| |
| .sum_exec_runtime = 0, \
| |
| }
| |
| | |
| #ifdef CONFIG_PREEMPT_COUNT
| |
| #define PREEMPT_DISABLED (1 + PREEMPT_ENABLED)
| |
| #else
| |
| #define PREEMPT_DISABLED PREEMPT_ENABLED
| |
| #endif
| |
| | |
| /*
| |
| * Disable preemption until the scheduler is running.
| |
| * Reset by start_kernel()->sched_init()->init_idle().
| |
| *
| |
| * We include PREEMPT_ACTIVE to avoid cond_resched() from working
| |
| * before the scheduler is active -- see should_resched().
| |
| */
| |
| #define INIT_PREEMPT_COUNT (PREEMPT_DISABLED + PREEMPT_ACTIVE)
| |
| | |
| /**
| |
| * struct thread_group_cputimer - thread group interval timer counts
| |
| * @cputime: thread group interval timers.
| |
| * @running: non-zero when there are timers running and
| |
| * @cputime receives updates.
| |
| * @lock: lock for fields in this struct.
| |
| *
| |
| * This structure contains the version of task_cputime, above, that is
| |
| * used for thread group CPU timer calculations.
| |
| */
| |
| struct thread_group_cputimer {
| |
| struct task_cputime cputime;
| |
| int running;
| |
| raw_spinlock_t lock;
| |
| };
| |
| | |
| #include <linux/rwsem.h>
| |
| struct autogroup;
| |
| | |
| /*
| |
| * NOTE! "signal_struct" does not have its own
| |
| * locking, because a shared signal_struct always
| |
| * implies a shared sighand_struct, so locking
| |
| * sighand_struct is always a proper superset of
| |
| * the locking of signal_struct.
| |
| */
| |
| struct signal_struct {
| |
| atomic_t sigcnt;
| |
| atomic_t live;
| |
| int nr_threads;
| |
| struct list_head thread_head;
| |
| | |
| wait_queue_head_t wait_chldexit; /* for wait4() */
| |
| | |
| /* current thread group signal load-balancing target: */
| |
| struct task_struct *curr_target;
| |
| | |
| /* shared signal handling: */
| |
| struct sigpending shared_pending;
| |
| | |
| /* thread group exit support */
| |
| int group_exit_code;
| |
| /* overloaded:
| |
| * - notify group_exit_task when ->count is equal to notify_count
| |
| * - everyone except group_exit_task is stopped during signal delivery
| |
| * of fatal signals, group_exit_task processes the signal.
| |
| */
| |
| int notify_count;
| |
| struct task_struct *group_exit_task;
| |
| | |
| /* thread group stop support, overloads group_exit_code too */
| |
| int group_stop_count;
| |
| unsigned int flags; /* see SIGNAL_* flags below */
| |
| | |
| /*
| |
| * PR_SET_CHILD_SUBREAPER marks a process, like a service
| |
| * manager, to re-parent orphan (double-forking) child processes
| |
| * to this process instead of 'init'. The service manager is
| |
| * able to receive SIGCHLD signals and is able to investigate
| |
| * the process until it calls wait(). All children of this
| |
| * process will inherit a flag if they should look for a
| |
| * child_subreaper process at exit.
| |
| */
| |
| unsigned int is_child_subreaper:1;
| |
| unsigned int has_child_subreaper:1;
| |
| | |
| /* POSIX.1b Interval Timers */
| |
| int posix_timer_id;
| |
| struct list_head posix_timers;
| |
| | |
| /* ITIMER_REAL timer for the process */
| |
| struct hrtimer real_timer;
| |
| struct pid *leader_pid;
| |
| ktime_t it_real_incr;
| |
| | |
| /*
| |
| * ITIMER_PROF and ITIMER_VIRTUAL timers for the process, we use
| |
| * CPUCLOCK_PROF and CPUCLOCK_VIRT for indexing array as these
| |
| * values are defined to 0 and 1 respectively
| |
| */
| |
| struct cpu_itimer it[2];
| |
| | |
| /*
| |
| * Thread group totals for process CPU timers.
| |
| * See thread_group_cputimer(), et al, for details.
| |
| */
| |
| struct thread_group_cputimer cputimer;
| |
| | |
| /* Earliest-expiration cache. */
| |
| struct task_cputime cputime_expires;
| |
| | |
| struct list_head cpu_timers[3];
| |
| | |
| struct pid *tty_old_pgrp;
| |
| | |
| /* boolean value for session group leader */
| |
| int leader;
| |
| | |
| struct tty_struct *tty; /* NULL if no tty */
| |
| | |
| #ifdef CONFIG_SCHED_AUTOGROUP
| |
| struct autogroup *autogroup;
| |
| #endif
| |
| /*
| |
| * Cumulative resource counters for dead threads in the group,
| |
| * and for reaped dead child processes forked by this group.
| |
| * Live threads maintain their own counters and add to these
| |
| * in __exit_signal, except for the group leader.
| |
| */
| |
| cputime_t utime, stime, cutime, cstime;
| |
| cputime_t gtime;
| |
| cputime_t cgtime;
| |
| #ifndef CONFIG_VIRT_CPU_ACCOUNTING_NATIVE
| |
| struct cputime prev_cputime;
| |
| #endif
| |
| unsigned long nvcsw, nivcsw, cnvcsw, cnivcsw;
| |
| unsigned long min_flt, maj_flt, cmin_flt, cmaj_flt;
| |
| unsigned long inblock, oublock, cinblock, coublock;
| |
| unsigned long maxrss, cmaxrss;
| |
| struct task_io_accounting ioac;
| |
| | |
| /*
| |
| * Cumulative ns of schedule CPU time fo dead threads in the
| |
| * group, not including a zombie group leader, (This only differs
| |
| * from jiffies_to_ns(utime + stime) if sched_clock uses something
| |
| * other than jiffies.)
| |
| */
| |
| unsigned long long sum_sched_runtime;
| |
| | |
| /*
| |
| * We don't bother to synchronize most readers of this at all,
| |
| * because there is no reader checking a limit that actually needs
| |
| * to get both rlim_cur and rlim_max atomically, and either one
| |
| * alone is a single word that can safely be read normally.
| |
| * getrlimit/setrlimit use task_lock(current->group_leader) to
| |
| * protect this instead of the siglock, because they really
| |
| * have no need to disable irqs.
| |
| */
| |
| struct rlimit rlim[RLIM_NLIMITS];
| |
| | |
| #ifdef CONFIG_BSD_PROCESS_ACCT
| |
| struct pacct_struct pacct; /* per-process accounting information */
| |
| #endif
| |
| #ifdef CONFIG_TASKSTATS
| |
| struct taskstats *stats;
| |
| #endif
| |
| #ifdef CONFIG_AUDIT
| |
| unsigned audit_tty;
| |
| unsigned audit_tty_log_passwd;
| |
| struct tty_audit_buf *tty_audit_buf;
| |
| #endif
| |
| #ifdef CONFIG_CGROUPS
| |
| /*
| |
| * group_rwsem prevents new tasks from entering the threadgroup and
| |
| * member tasks from exiting,a more specifically, setting of
| |
| * PF_EXITING. fork and exit paths are protected with this rwsem
| |
| * using threadgroup_change_begin/end(). Users which require
| |
| * threadgroup to remain stable should use threadgroup_[un]lock()
| |
| * which also takes care of exec path. Currently, cgroup is the
| |
| * only user.
| |
| */
| |
| struct rw_semaphore group_rwsem;
| |
| #endif
| |
| | |
| oom_flags_t oom_flags;
| |
| short oom_score_adj; /* OOM kill score adjustment */
| |
| short oom_score_adj_min; /* OOM kill score adjustment min value.
| |
| * Only settable by CAP_SYS_RESOURCE. */
| |
| | |
| struct mutex cred_guard_mutex; /* guard against foreign influences on
| |
| * credential calculations
| |
| * (notably. ptrace) */
| |
| };
| |
| | |
| /*
| |
| * Bits in flags field of signal_struct.
| |
| */
| |
| #define SIGNAL_STOP_STOPPED 0x00000001 /* job control stop in effect */
| |
| #define SIGNAL_STOP_CONTINUED 0x00000002 /* SIGCONT since WCONTINUED reap */
| |
| #define SIGNAL_GROUP_EXIT 0x00000004 /* group exit in progress */
| |
| #define SIGNAL_GROUP_COREDUMP 0x00000008 /* coredump in progress */
| |
| /*
| |
| * Pending notifications to parent.
| |
| */
| |
| #define SIGNAL_CLD_STOPPED 0x00000010
| |
| #define SIGNAL_CLD_CONTINUED 0x00000020
| |
| #define SIGNAL_CLD_MASK (SIGNAL_CLD_STOPPED|SIGNAL_CLD_CONTINUED)
| |
| | |
| #define SIGNAL_UNKILLABLE 0x00000040 /* for init: ignore fatal signals */
| |
| | |
| /* If true, all threads except ->group_exit_task have pending SIGKILL */
| |
| static inline int signal_group_exit(const struct signal_struct *sig)
| |
| {
| |
| return (sig->flags & SIGNAL_GROUP_EXIT) ||
| |
| (sig->group_exit_task != NULL);
| |
| }
| |
| | |
| /*
| |
| * Some day this will be a full-fledged user tracking system..
| |
| */
| |
| struct user_struct {
| |
| atomic_t __count; /* reference count */
| |
| atomic_t processes; /* How many processes does this user have? */
| |
| atomic_t files; /* How many open files does this user have? */
| |
| atomic_t sigpending; /* How many pending signals does this user have? */
| |
| #ifdef CONFIG_INOTIFY_USER
| |
| atomic_t inotify_watches; /* How many inotify watches does this user have? */
| |
| atomic_t inotify_devs; /* How many inotify devs does this user have opened? */
| |
| #endif
| |
| #ifdef CONFIG_FANOTIFY
| |
| atomic_t fanotify_listeners;
| |
| #endif
| |
| #ifdef CONFIG_EPOLL
| |
| atomic_long_t epoll_watches; /* The number of file descriptors currently watched */
| |
| #endif
| |
| #ifdef CONFIG_POSIX_MQUEUE
| |
| /* protected by mq_lock */
| |
| unsigned long mq_bytes; /* How many bytes can be allocated to mqueue? */
| |
| #endif
| |
| unsigned long locked_shm; /* How many pages of mlocked shm ? */
| |
| | |
| #ifdef CONFIG_KEYS
| |
| struct key *uid_keyring; /* UID specific keyring */
| |
| struct key *session_keyring; /* UID's default session keyring */
| |
| #endif
| |
| | |
| /* Hash table maintenance information */
| |
| struct hlist_node uidhash_node;
| |
| kuid_t uid;
| |
| | |
| #ifdef CONFIG_PERF_EVENTS
| |
| atomic_long_t locked_vm;
| |
| #endif
| |
| };
| |
| | |
| extern int uids_sysfs_init(void);
| |
| | |
| extern struct user_struct *find_user(kuid_t);
| |
| | |
| extern struct user_struct root_user;
| |
| #define INIT_USER (&root_user)
| |
| | |
| | |
| struct backing_dev_info;
| |
| struct reclaim_state;
| |
| | |
| #if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
| |
| struct sched_info {
| |
| /* cumulative counters */
| |
| unsigned long pcount; /* # of times run on this cpu */
| |
| unsigned long long run_delay; /* time spent waiting on a runqueue */
| |
| | |
| /* timestamps */
| |
| unsigned long long last_arrival,/* when we last ran on a cpu */
| |
| last_queued; /* when we were last queued to run */
| |
| };
| |
| #endif /* defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT) */
| |
| | |
| #ifdef CONFIG_TASK_DELAY_ACCT
| |
| struct task_delay_info {
| |
| spinlock_t lock;
| |
| unsigned int flags; /* Private per-task flags */
| |
| | |
| /* For each stat XXX, add following, aligned appropriately
| |
| *
| |
| * struct timespec XXX_start, XXX_end;
| |
| * u64 XXX_delay;
| |
| * u32 XXX_count;
| |
| *
| |
| * Atomicity of updates to XXX_delay, XXX_count protected by
| |
| * single lock above (split into XXX_lock if contention is an issue).
| |
| */
| |
| | |
| /*
| |
| * XXX_count is incremented on every XXX operation, the delay
| |
| * associated with the operation is added to XXX_delay.
| |
| * XXX_delay contains the accumulated delay time in nanoseconds.
| |
| */
| |
| struct timespec blkio_start, blkio_end; /* Shared by blkio, swapin */
| |
| u64 blkio_delay; /* wait for sync block io completion */
| |
| u64 swapin_delay; /* wait for swapin block io completion */
| |
| u32 blkio_count; /* total count of the number of sync block */
| |
| /* io operations performed */
| |
| u32 swapin_count; /* total count of the number of swapin block */
| |
| /* io operations performed */
| |
| | |
| struct timespec freepages_start, freepages_end;
| |
| u64 freepages_delay; /* wait for memory reclaim */
| |
| u32 freepages_count; /* total count of memory reclaim */
| |
| };
| |
| #endif /* CONFIG_TASK_DELAY_ACCT */
| |
| | |
| static inline int sched_info_on(void)
| |
| {
| |
| #ifdef CONFIG_SCHEDSTATS
| |
| return 1;
| |
| #elif defined(CONFIG_TASK_DELAY_ACCT)
| |
| extern int delayacct_on;
| |
| return delayacct_on;
| |
| #else
| |
| return 0;
| |
| #endif
| |
| }
| |
| | |
| enum cpu_idle_type {
| |
| CPU_IDLE,
| |
| CPU_NOT_IDLE,
| |
| CPU_NEWLY_IDLE,
| |
| CPU_MAX_IDLE_TYPES
| |
| };
| |
| | |
| /*
| |
| * Increase resolution of cpu_power calculations
| |
| */
| |
| #define SCHED_POWER_SHIFT 10
| |
| #define SCHED_POWER_SCALE (1L << SCHED_POWER_SHIFT)
| |
| | |
| /*
| |
| * sched-domains (multiprocessor balancing) declarations:
| |
| */
| |
| #ifdef CONFIG_SMP
| |
| #define SD_LOAD_BALANCE 0x0001 /* Do load balancing on this domain. */
| |
| #define SD_BALANCE_NEWIDLE 0x0002 /* Balance when about to become idle */
| |
| #define SD_BALANCE_EXEC 0x0004 /* Balance on exec */
| |
| #define SD_BALANCE_FORK 0x0008 /* Balance on fork, clone */
| |
| #define SD_BALANCE_WAKE 0x0010 /* Balance on wakeup */
| |
| #define SD_WAKE_AFFINE 0x0020 /* Wake task to waking CPU */
| |
| #define SD_SHARE_CPUPOWER 0x0080 /* Domain members share cpu power */
| |
| #define SD_SHARE_PKG_RESOURCES 0x0200 /* Domain members share cpu pkg resources */
| |
| #define SD_SERIALIZE 0x0400 /* Only a single load balancing instance */
| |
| #define SD_ASYM_PACKING 0x0800 /* Place busy groups earlier in the domain */
| |
| #define SD_PREFER_SIBLING 0x1000 /* Prefer to place tasks in a sibling domain */
| |
| #define SD_OVERLAP 0x2000 /* sched_domains of this level overlap */
| |
| #define SD_NUMA 0x4000 /* cross-node balancing */
| |
| | |
| extern int __weak arch_sd_sibiling_asym_packing(void);
| |
| | |
| struct sched_domain_attr {
| |
| int relax_domain_level;
| |
| };
| |
| | |
| #define SD_ATTR_INIT (struct sched_domain_attr) { \
| |
| .relax_domain_level = -1, \
| |
| }
| |
| | |
| extern int sched_domain_level_max;
| |
| | |
| struct sched_group;
| |
| | |
| struct sched_domain {
| |
| /* These fields must be setup */
| |
| struct sched_domain *parent; /* top domain must be null terminated */
| |
| struct sched_domain *child; /* bottom domain must be null terminated */
| |
| struct sched_group *groups; /* the balancing groups of the domain */
| |
| unsigned long min_interval; /* Minimum balance interval ms */
| |
| unsigned long max_interval; /* Maximum balance interval ms */
| |
| unsigned int busy_factor; /* less balancing by factor if busy */
| |
| unsigned int imbalance_pct; /* No balance until over watermark */
| |
| unsigned int cache_nice_tries; /* Leave cache hot tasks for # tries */
| |
| unsigned int busy_idx;
| |
| unsigned int idle_idx;
| |
| unsigned int newidle_idx;
| |
| unsigned int wake_idx;
| |
| unsigned int forkexec_idx;
| |
| unsigned int smt_gain;
| |
| | |
| int nohz_idle; /* NOHZ IDLE status */
| |
| int flags; /* See SD_* */
| |
| int level;
| |
| | |
| /* Runtime fields. */
| |
| unsigned long last_balance; /* init to jiffies. units in jiffies */
| |
| unsigned int balance_interval; /* initialise to 1. units in ms. */
| |
| unsigned int nr_balance_failed; /* initialise to 0 */
| |
| | |
| /* idle_balance() stats */
| |
| u64 max_newidle_lb_cost;
| |
| unsigned long next_decay_max_lb_cost;
| |
| | |
| #ifdef CONFIG_SCHEDSTATS
| |
| /* load_balance() stats */
| |
| unsigned int lb_count[CPU_MAX_IDLE_TYPES];
| |
| unsigned int lb_failed[CPU_MAX_IDLE_TYPES];
| |
| unsigned int lb_balanced[CPU_MAX_IDLE_TYPES];
| |
| unsigned int lb_imbalance[CPU_MAX_IDLE_TYPES];
| |
| unsigned int lb_gained[CPU_MAX_IDLE_TYPES];
| |
| unsigned int lb_hot_gained[CPU_MAX_IDLE_TYPES];
| |
| unsigned int lb_nobusyg[CPU_MAX_IDLE_TYPES];
| |
| unsigned int lb_nobusyq[CPU_MAX_IDLE_TYPES];
| |
| | |
| /* Active load balancing */
| |
| unsigned int alb_count;
| |
| unsigned int alb_failed;
| |
| unsigned int alb_pushed;
| |
| | |
| /* SD_BALANCE_EXEC stats */
| |
| unsigned int sbe_count;
| |
| unsigned int sbe_balanced;
| |
| unsigned int sbe_pushed;
| |
| | |
| /* SD_BALANCE_FORK stats */
| |
| unsigned int sbf_count;
| |
| unsigned int sbf_balanced;
| |
| unsigned int sbf_pushed;
| |
| | |
| /* try_to_wake_up() stats */
| |
| unsigned int ttwu_wake_remote;
| |
| unsigned int ttwu_move_affine;
| |
| unsigned int ttwu_move_balance;
| |
| #endif
| |
| #ifdef CONFIG_SCHED_DEBUG
| |
| char *name;
| |
| #endif
| |
| union {
| |
| void *private; /* used during construction */
| |
| struct rcu_head rcu; /* used during destruction */
| |
| };
| |
| | |
| unsigned int span_weight;
| |
| /*
| |
| * Span of all CPUs in this domain.
| |
| *
| |
| * NOTE: this field is variable length. (Allocated dynamically
| |
| * by attaching extra space to the end of the structure,
| |
| * depending on how many CPUs the kernel has booted up with)
| |
| */
| |
| unsigned long span[0];
| |
| };
| |
| | |
| static inline struct cpumask *sched_domain_span(struct sched_domain *sd)
| |
| {
| |
| return to_cpumask(sd->span);
| |
| }
| |
| | |
| extern void partition_sched_domains(int ndoms_new, cpumask_var_t doms_new[],
| |
| struct sched_domain_attr *dattr_new);
| |
| | |
| /* Allocate an array of sched domains, for partition_sched_domains(). */
| |
| cpumask_var_t *alloc_sched_domains(unsigned int ndoms);
| |
| void free_sched_domains(cpumask_var_t doms[], unsigned int ndoms);
| |
| | |
| bool cpus_share_cache(int this_cpu, int that_cpu);
| |
| | |
| #else /* CONFIG_SMP */
| |
| | |
| struct sched_domain_attr;
| |
| | |
| static inline void
| |
| partition_sched_domains(int ndoms_new, cpumask_var_t doms_new[],
| |
| struct sched_domain_attr *dattr_new)
| |
| {
| |
| }
| |
| | |
| static inline bool cpus_share_cache(int this_cpu, int that_cpu)
| |
| {
| |
| return true;
| |
| }
| |
| | |
| #endif /* !CONFIG_SMP */
| |
| | |
| | |
| struct io_context; /* See blkdev.h */
| |
| | |
| | |
| #ifdef ARCH_HAS_PREFETCH_SWITCH_STACK
| |
| extern void prefetch_stack(struct task_struct *t);
| |
| #else
| |
| static inline void prefetch_stack(struct task_struct *t) { }
| |
| #endif
| |
| | |
| struct audit_context; /* See audit.c */
| |
| struct mempolicy;
| |
| struct pipe_inode_info;
| |
| struct uts_namespace;
| |
| | |
| struct load_weight {
| |
| unsigned long weight;
| |
| u32 inv_weight;
| |
| };
| |
| | |
| struct sched_avg {
| |
| /*
| |
| * These sums represent an infinite geometric series and so are bound
| |
| * above by 1024/(1-y). Thus we only need a u32 to store them for all
| |
| * choices of y < 1-2^(-32)*1024.
| |
| */
| |
| u32 runnable_avg_sum, runnable_avg_period;
| |
| u64 last_runnable_update;
| |
| s64 decay_count;
| |
| unsigned long load_avg_contrib;
| |
| };
| |
| | |
| #ifdef CONFIG_SCHEDSTATS
| |
| struct sched_statistics {
| |
| u64 wait_start;
| |
| u64 wait_max;
| |
| u64 wait_count;
| |
| u64 wait_sum;
| |
| u64 iowait_count;
| |
| u64 iowait_sum;
| |
| | |
| u64 sleep_start;
| |
| u64 sleep_max;
| |
| s64 sum_sleep_runtime;
| |
| | |
| u64 block_start;
| |
| u64 block_max;
| |
| u64 exec_max;
| |
| u64 slice_max;
| |
| | |
| u64 nr_migrations_cold;
| |
| u64 nr_failed_migrations_affine;
| |
| u64 nr_failed_migrations_running;
| |
| u64 nr_failed_migrations_hot;
| |
| u64 nr_forced_migrations;
| |
| | |
| u64 nr_wakeups;
| |
| u64 nr_wakeups_sync;
| |
| u64 nr_wakeups_migrate;
| |
| u64 nr_wakeups_local;
| |
| u64 nr_wakeups_remote;
| |
| u64 nr_wakeups_affine;
| |
| u64 nr_wakeups_affine_attempts;
| |
| u64 nr_wakeups_passive;
| |
| u64 nr_wakeups_idle;
| |
| };
| |
| #endif
| |
| | |
| struct sched_entity {
| |
| struct load_weight load; /* for load-balancing */
| |
| struct rb_node run_node;
| |
| struct list_head group_node;
| |
| unsigned int on_rq;
| |
| | |
| u64 exec_start;
| |
| u64 sum_exec_runtime;
| |
| u64 vruntime;
| |
| u64 prev_sum_exec_runtime;
| |
| | |
| u64 nr_migrations;
| |
| | |
| #ifdef CONFIG_SCHEDSTATS
| |
| struct sched_statistics statistics;
| |
| #endif
| |
| | |
| #ifdef CONFIG_FAIR_GROUP_SCHED
| |
| struct sched_entity *parent;
| |
| /* rq on which this entity is (to be) queued: */
| |
| struct cfs_rq *cfs_rq;
| |
| /* rq "owned" by this entity/group: */
| |
| struct cfs_rq *my_q;
| |
| #endif
| |
| | |
| #ifdef CONFIG_SMP
| |
| /* Per-entity load-tracking */
| |
| struct sched_avg avg;
| |
| #endif
| |
| };
| |
| | |
| struct sched_rt_entity {
| |
| struct list_head run_list;
| |
| unsigned long timeout;
| |
| unsigned long watchdog_stamp;
| |
| unsigned int time_slice;
| |
| | |
| struct sched_rt_entity *back;
| |
| #ifdef CONFIG_RT_GROUP_SCHED
| |
| struct sched_rt_entity *parent;
| |
| /* rq on which this entity is (to be) queued: */
| |
| struct rt_rq *rt_rq;
| |
| /* rq "owned" by this entity/group: */
| |
| struct rt_rq *my_q;
| |
| #endif
| |
| };
| |
| | |
| | |
| struct rcu_node;
| |
| | |
| enum perf_event_task_context {
| |
| perf_invalid_context = -1,
| |
| perf_hw_context = 0,
| |
| perf_sw_context,
| |
| perf_nr_task_contexts,
| |
| };
| |
| | |
| struct task_struct { | | struct task_struct { |
| volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ | | volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */ |
| Zeile 1.480: |
Zeile 435: |
| #endif | | #endif |
| }; | | }; |
| | </source> |
| | </p> |
|
| |
|
| /* Future-safe accessor for struct task_struct's cpus_allowed. */ | | <br /> |
| #define tsk_cpus_allowed(tsk) (&(tsk)->cpus_allowed)
| | <p> |
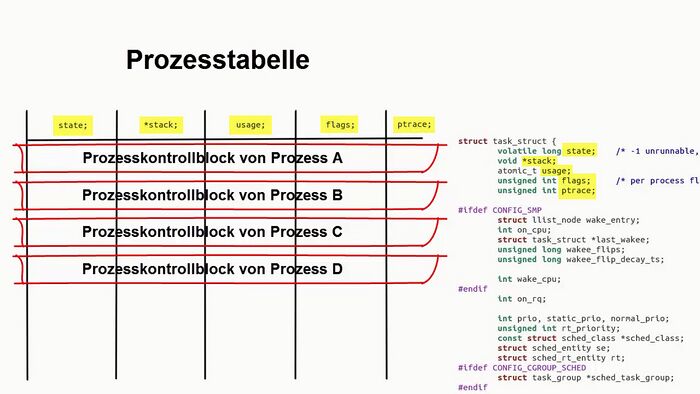
| | Das folgende Bild wurde im [http://youtu.be/QeerwZOO9bw Video] erläutert: |
| | </p> |
|
| |
|
| #define TNF_MIGRATED 0x01
| | <loop_figure description="Der Zusammenhang zwischen task_struct und den Spalten der Prozesstabelle" show_copyright="true" copyright="CC-BY" id="5fa97870a7045"> |
| #define TNF_NO_GROUP 0x02
| | [[Datei:task_struct_vs_ptable.jpg|700px]] |
| #define TNF_SHARED 0x04
| | </loop_figure> |
| #define TNF_FAULT_LOCAL 0x08
| |
|
| |
|
| #ifdef CONFIG_NUMA_BALANCING
| | <br /> |
| extern void task_numa_fault(int last_node, int node, int pages, int flags);
| | === Aufgabe 1 === |
| extern pid_t task_numa_group_id(struct task_struct *p);
| | <p> |
| extern void set_numabalancing_state(bool enabled);
| | <loop_area type="task"> |
| extern void task_numa_free(struct task_struct *p);
| | <loop_task title="Die Spalten der Prozesstabelle" id="5fa97870a705a"> |
| | <p> |
| | Im [http://youtu.be/QeerwZOO9bw Video] wurde der Zusammenhang zwischen der Datenstruktur ''task_struct'' und den Spalten der Prozesstabelle erläutert. |
| | </p> |
| | <p> |
| | Was schätzt du:<br /> |
| | Aus wievielen Spalten besteht in etwa die Prozesstabelle? |
| | </p> |
| | <p> |
| | * Aus 5 bis 10 Spalten. |
| | * Aus 25 bis 30 Spalten. |
| | * Aus mehr als 50 Spalten. |
| | </p> |
| | <spoiler text="Hinweis"> |
| | <p> |
| | Aus wievielen Zeilen Quelltext besteht die Deklaration des ''task_struct''? |
| | </p> |
| | </spoiler> |
| | </loop_task> |
| | </loop_area> |
| | </p> |
|
| |
|
| extern unsigned int sysctl_numa_balancing_migrate_deferred;
| | <br /> |
| #else
| |
| static inline void task_numa_fault(int last_node, int node, int pages,
| |
| int flags)
| |
| {
| |
| }
| |
| static inline pid_t task_numa_group_id(struct task_struct *p)
| |
| {
| |
| return 0;
| |
| }
| |
| static inline void set_numabalancing_state(bool enabled)
| |
| {
| |
| }
| |
| static inline void task_numa_free(struct task_struct *p)
| |
| {
| |
| }
| |
| #endif
| |
|
| |
|
| static inline struct pid *task_pid(struct task_struct *task)
| | == Beispiel: Prozesskontrollblock unter Linux == |
| {
| | <p> |
| return task->pids[PIDTYPE_PID].pid;
| | <loop_area type="notice">'''Weiterführende Literatur''' |
| }
| | <p> |
| | | <cite id="5fa97870a706d">Achilles+2006</cite> zeigt in Kapitel 3.1 den ''Linux Process Control Block''. Die Lektüre dieser Quelle sei ausdrücklich empfohlen. |
| static inline struct pid *task_tgid(struct task_struct *task)
| | </p> |
| {
| | <p> |
| return task->group_leader->pids[PIDTYPE_PID].pid;
| | <small> |
| }
| | Studierende sind oftmals berechtigt, eine PDF-Version dieses Buches ohne entstehende Kosten [[Hinweise für Studierende#Downloadbare Bücher von Springerlink|über ihre Hochschulen von Springerlink zu beziehen.]] |
| | | </small> |
| /*
| | </p> |
| * Without tasklist or rcu lock it is not safe to dereference
| | </loop_area> |
| * the result of task_pgrp/task_session even if task == current,
| |
| * we can race with another thread doing sys_setsid/sys_setpgid.
| |
| */
| |
| static inline struct pid *task_pgrp(struct task_struct *task)
| |
| {
| |
| return task->group_leader->pids[PIDTYPE_PGID].pid;
| |
| }
| |
| | |
| static inline struct pid *task_session(struct task_struct *task)
| |
| {
| |
| return task->group_leader->pids[PIDTYPE_SID].pid;
| |
| }
| |
| | |
| struct pid_namespace;
| |
| | |
| /*
| |
| * the helpers to get the task's different pids as they are seen
| |
| * from various namespaces
| |
| *
| |
| * task_xid_nr() : global id, i.e. the id seen from the init namespace;
| |
| * task_xid_vnr() : virtual id, i.e. the id seen from the pid namespace of
| |
| * current.
| |
| * task_xid_nr_ns() : id seen from the ns specified;
| |
| *
| |
| * set_task_vxid() : assigns a virtual id to a task;
| |
| *
| |
| * see also pid_nr() etc in include/linux/pid.h
| |
| */
| |
| pid_t __task_pid_nr_ns(struct task_struct *task, enum pid_type type,
| |
| struct pid_namespace *ns);
| |
| | |
| static inline pid_t task_pid_nr(struct task_struct *tsk)
| |
| {
| |
| return tsk->pid;
| |
| }
| |
| | |
| static inline pid_t task_pid_nr_ns(struct task_struct *tsk,
| |
| struct pid_namespace *ns)
| |
| {
| |
| return __task_pid_nr_ns(tsk, PIDTYPE_PID, ns);
| |
| }
| |
| | |
| static inline pid_t task_pid_vnr(struct task_struct *tsk)
| |
| {
| |
| return __task_pid_nr_ns(tsk, PIDTYPE_PID, NULL);
| |
| }
| |
| | |
| | |
| static inline pid_t task_tgid_nr(struct task_struct *tsk)
| |
| {
| |
| return tsk->tgid;
| |
| }
| |
| | |
| pid_t task_tgid_nr_ns(struct task_struct *tsk, struct pid_namespace *ns);
| |
| | |
| static inline pid_t task_tgid_vnr(struct task_struct *tsk)
| |
| {
| |
| return pid_vnr(task_tgid(tsk));
| |
| }
| |
| | |
| | |
| static int pid_alive(const struct task_struct *p);
| |
| static inline pid_t task_ppid_nr_ns(const struct task_struct *tsk, struct pid_namespace *ns)
| |
| {
| |
| pid_t pid = 0;
| |
| | |
| rcu_read_lock();
| |
| if (pid_alive(tsk))
| |
| pid = task_tgid_nr_ns(rcu_dereference(tsk->real_parent), ns);
| |
| rcu_read_unlock();
| |
| | |
| return pid;
| |
| }
| |
| | |
| static inline pid_t task_ppid_nr(const struct task_struct *tsk)
| |
| {
| |
| return task_ppid_nr_ns(tsk, &init_pid_ns);
| |
| }
| |
| | |
| static inline pid_t task_pgrp_nr_ns(struct task_struct *tsk,
| |
| struct pid_namespace *ns)
| |
| {
| |
| return __task_pid_nr_ns(tsk, PIDTYPE_PGID, ns);
| |
| }
| |
| | |
| static inline pid_t task_pgrp_vnr(struct task_struct *tsk)
| |
| {
| |
| return __task_pid_nr_ns(tsk, PIDTYPE_PGID, NULL);
| |
| }
| |
| | |
| | |
| static inline pid_t task_session_nr_ns(struct task_struct *tsk,
| |
| struct pid_namespace *ns)
| |
| {
| |
| return __task_pid_nr_ns(tsk, PIDTYPE_SID, ns);
| |
| }
| |
| | |
| static inline pid_t task_session_vnr(struct task_struct *tsk)
| |
| {
| |
| return __task_pid_nr_ns(tsk, PIDTYPE_SID, NULL);
| |
| }
| |
| | |
| /* obsolete, do not use */
| |
| static inline pid_t task_pgrp_nr(struct task_struct *tsk)
| |
| {
| |
| return task_pgrp_nr_ns(tsk, &init_pid_ns);
| |
| }
| |
| | |
| /**
| |
| * pid_alive - check that a task structure is not stale
| |
| * @p: Task structure to be checked.
| |
| *
| |
| * Test if a process is not yet dead (at most zombie state)
| |
| * If pid_alive fails, then pointers within the task structure
| |
| * can be stale and must not be dereferenced.
| |
| *
| |
| * Return: 1 if the process is alive. 0 otherwise.
| |
| */
| |
| static inline int pid_alive(const struct task_struct *p)
| |
| {
| |
| return p->pids[PIDTYPE_PID].pid != NULL;
| |
| }
| |
| | |
| /**
| |
| * is_global_init - check if a task structure is init
| |
| * @tsk: Task structure to be checked.
| |
| *
| |
| * Check if a task structure is the first user space task the kernel created.
| |
| *
| |
| * Return: 1 if the task structure is init. 0 otherwise.
| |
| */
| |
| static inline int is_global_init(struct task_struct *tsk)
| |
| {
| |
| return tsk->pid == 1;
| |
| }
| |
| | |
| extern struct pid *cad_pid;
| |
| | |
| extern void free_task(struct task_struct *tsk);
| |
| #define get_task_struct(tsk) do { atomic_inc(&(tsk)->usage); } while(0)
| |
| | |
| extern void __put_task_struct(struct task_struct *t);
| |
| | |
| static inline void put_task_struct(struct task_struct *t)
| |
| {
| |
| if (atomic_dec_and_test(&t->usage))
| |
| __put_task_struct(t);
| |
| }
| |
| | |
| #ifdef CONFIG_VIRT_CPU_ACCOUNTING_GEN
| |
| extern void task_cputime(struct task_struct *t,
| |
| cputime_t *utime, cputime_t *stime);
| |
| extern void task_cputime_scaled(struct task_struct *t,
| |
| cputime_t *utimescaled, cputime_t *stimescaled);
| |
| extern cputime_t task_gtime(struct task_struct *t);
| |
| #else
| |
| static inline void task_cputime(struct task_struct *t,
| |
| cputime_t *utime, cputime_t *stime)
| |
| {
| |
| if (utime)
| |
| *utime = t->utime;
| |
| if (stime)
| |
| *stime = t->stime;
| |
| }
| |
| | |
| static inline void task_cputime_scaled(struct task_struct *t,
| |
| cputime_t *utimescaled,
| |
| cputime_t *stimescaled)
| |
| {
| |
| if (utimescaled)
| |
| *utimescaled = t->utimescaled;
| |
| if (stimescaled)
| |
| *stimescaled = t->stimescaled;
| |
| }
| |
| | |
| static inline cputime_t task_gtime(struct task_struct *t)
| |
| {
| |
| return t->gtime;
| |
| }
| |
| #endif
| |
| extern void task_cputime_adjusted(struct task_struct *p, cputime_t *ut, cputime_t *st);
| |
| extern void thread_group_cputime_adjusted(struct task_struct *p, cputime_t *ut, cputime_t *st);
| |
| | |
| /*
| |
| * Per process flags
| |
| */
| |
| #define PF_EXITING 0x00000004 /* getting shut down */
| |
| #define PF_EXITPIDONE 0x00000008 /* pi exit done on shut down */
| |
| #define PF_VCPU 0x00000010 /* I'm a virtual CPU */
| |
| #define PF_WQ_WORKER 0x00000020 /* I'm a workqueue worker */
| |
| #define PF_FORKNOEXEC 0x00000040 /* forked but didn't exec */
| |
| #define PF_MCE_PROCESS 0x00000080 /* process policy on mce errors */
| |
| #define PF_SUPERPRIV 0x00000100 /* used super-user privileges */
| |
| #define PF_DUMPCORE 0x00000200 /* dumped core */
| |
| #define PF_SIGNALED 0x00000400 /* killed by a signal */
| |
| #define PF_MEMALLOC 0x00000800 /* Allocating memory */
| |
| #define PF_NPROC_EXCEEDED 0x00001000 /* set_user noticed that RLIMIT_NPROC was exceeded */
| |
| #define PF_USED_MATH 0x00002000 /* if unset the fpu must be initialized before use */
| |
| #define PF_USED_ASYNC 0x00004000 /* used async_schedule*(), used by module init */
| |
| #define PF_NOFREEZE 0x00008000 /* this thread should not be frozen */
| |
| #define PF_FROZEN 0x00010000 /* frozen for system suspend */
| |
| #define PF_FSTRANS 0x00020000 /* inside a filesystem transaction */
| |
| #define PF_KSWAPD 0x00040000 /* I am kswapd */
| |
| #define PF_MEMALLOC_NOIO 0x00080000 /* Allocating memory without IO involved */
| |
| #define PF_LESS_THROTTLE 0x00100000 /* Throttle me less: I clean memory */
| |
| #define PF_KTHREAD 0x00200000 /* I am a kernel thread */
| |
| #define PF_RANDOMIZE 0x00400000 /* randomize virtual address space */
| |
| #define PF_SWAPWRITE 0x00800000 /* Allowed to write to swap */
| |
| #define PF_SPREAD_PAGE 0x01000000 /* Spread page cache over cpuset */
| |
| #define PF_SPREAD_SLAB 0x02000000 /* Spread some slab caches over cpuset */
| |
| #define PF_NO_SETAFFINITY 0x04000000 /* Userland is not allowed to meddle with cpus_allowed */
| |
| #define PF_MCE_EARLY 0x08000000 /* Early kill for mce process policy */
| |
| #define PF_MEMPOLICY 0x10000000 /* Non-default NUMA mempolicy */
| |
| #define PF_MUTEX_TESTER 0x20000000 /* Thread belongs to the rt mutex tester */
| |
| #define PF_FREEZER_SKIP 0x40000000 /* Freezer should not count it as freezable */
| |
| #define PF_SUSPEND_TASK 0x80000000 /* this thread called freeze_processes and should not be frozen */
| |
| | |
| /*
| |
| * Only the _current_ task can read/write to tsk->flags, but other
| |
| * tasks can access tsk->flags in readonly mode for example
| |
| * with tsk_used_math (like during threaded core dumping).
| |
| * There is however an exception to this rule during ptrace
| |
| * or during fork: the ptracer task is allowed to write to the
| |
| * child->flags of its traced child (same goes for fork, the parent
| |
| * can write to the child->flags), because we're guaranteed the
| |
| * child is not running and in turn not changing child->flags
| |
| * at the same time the parent does it.
| |
| */
| |
| #define clear_stopped_child_used_math(child) do { (child)->flags &= ~PF_USED_MATH; } while (0)
| |
| #define set_stopped_child_used_math(child) do { (child)->flags |= PF_USED_MATH; } while (0)
| |
| #define clear_used_math() clear_stopped_child_used_math(current)
| |
| #define set_used_math() set_stopped_child_used_math(current)
| |
| #define conditional_stopped_child_used_math(condition, child) \
| |
| do { (child)->flags &= ~PF_USED_MATH, (child)->flags |= (condition) ? PF_USED_MATH : 0; } while (0)
| |
| #define conditional_used_math(condition) \
| |
| conditional_stopped_child_used_math(condition, current)
| |
| #define copy_to_stopped_child_used_math(child) \
| |
| do { (child)->flags &= ~PF_USED_MATH, (child)->flags |= current->flags & PF_USED_MATH; } while (0)
| |
| /* NOTE: this will return 0 or PF_USED_MATH, it will never return 1 */
| |
| #define tsk_used_math(p) ((p)->flags & PF_USED_MATH)
| |
| #define used_math() tsk_used_math(current)
| |
| | |
| /* __GFP_IO isn't allowed if PF_MEMALLOC_NOIO is set in current->flags */
| |
| static inline gfp_t memalloc_noio_flags(gfp_t flags)
| |
| {
| |
| if (unlikely(current->flags & PF_MEMALLOC_NOIO))
| |
| flags &= ~__GFP_IO;
| |
| return flags;
| |
| }
| |
| | |
| static inline unsigned int memalloc_noio_save(void)
| |
| {
| |
| unsigned int flags = current->flags & PF_MEMALLOC_NOIO;
| |
| current->flags |= PF_MEMALLOC_NOIO;
| |
| return flags;
| |
| }
| |
| | |
| static inline void memalloc_noio_restore(unsigned int flags)
| |
| {
| |
| current->flags = (current->flags & ~PF_MEMALLOC_NOIO) | flags;
| |
| }
| |
| | |
| /*
| |
| * task->jobctl flags
| |
| */
| |
| #define JOBCTL_STOP_SIGMASK 0xffff /* signr of the last group stop */
| |
| | |
| #define JOBCTL_STOP_DEQUEUED_BIT 16 /* stop signal dequeued */
| |
| #define JOBCTL_STOP_PENDING_BIT 17 /* task should stop for group stop */
| |
| #define JOBCTL_STOP_CONSUME_BIT 18 /* consume group stop count */
| |
| #define JOBCTL_TRAP_STOP_BIT 19 /* trap for STOP */
| |
| #define JOBCTL_TRAP_NOTIFY_BIT 20 /* trap for NOTIFY */
| |
| #define JOBCTL_TRAPPING_BIT 21 /* switching to TRACED */
| |
| #define JOBCTL_LISTENING_BIT 22 /* ptracer is listening for events */
| |
| | |
| #define JOBCTL_STOP_DEQUEUED (1 << JOBCTL_STOP_DEQUEUED_BIT)
| |
| #define JOBCTL_STOP_PENDING (1 << JOBCTL_STOP_PENDING_BIT)
| |
| #define JOBCTL_STOP_CONSUME (1 << JOBCTL_STOP_CONSUME_BIT)
| |
| #define JOBCTL_TRAP_STOP (1 << JOBCTL_TRAP_STOP_BIT)
| |
| #define JOBCTL_TRAP_NOTIFY (1 << JOBCTL_TRAP_NOTIFY_BIT)
| |
| #define JOBCTL_TRAPPING (1 << JOBCTL_TRAPPING_BIT)
| |
| #define JOBCTL_LISTENING (1 << JOBCTL_LISTENING_BIT)
| |
| | |
| #define JOBCTL_TRAP_MASK (JOBCTL_TRAP_STOP | JOBCTL_TRAP_NOTIFY)
| |
| #define JOBCTL_PENDING_MASK (JOBCTL_STOP_PENDING | JOBCTL_TRAP_MASK)
| |
| | |
| extern bool task_set_jobctl_pending(struct task_struct *task,
| |
| unsigned int mask);
| |
| extern void task_clear_jobctl_trapping(struct task_struct *task);
| |
| extern void task_clear_jobctl_pending(struct task_struct *task,
| |
| unsigned int mask);
| |
| | |
| #ifdef CONFIG_PREEMPT_RCU
| |
| | |
| #define RCU_READ_UNLOCK_BLOCKED (1 << 0) /* blocked while in RCU read-side. */
| |
| #define RCU_READ_UNLOCK_NEED_QS (1 << 1) /* RCU core needs CPU response. */
| |
| | |
| static inline void rcu_copy_process(struct task_struct *p)
| |
| {
| |
| p->rcu_read_lock_nesting = 0;
| |
| p->rcu_read_unlock_special = 0;
| |
| #ifdef CONFIG_TREE_PREEMPT_RCU
| |
| p->rcu_blocked_node = NULL;
| |
| #endif /* #ifdef CONFIG_TREE_PREEMPT_RCU */
| |
| #ifdef CONFIG_RCU_BOOST
| |
| p->rcu_boost_mutex = NULL;
| |
| #endif /* #ifdef CONFIG_RCU_BOOST */
| |
| INIT_LIST_HEAD(&p->rcu_node_entry);
| |
| }
| |
| | |
| #else
| |
| | |
| static inline void rcu_copy_process(struct task_struct *p)
| |
| {
| |
| }
| |
| | |
| #endif
| |
| | |
| static inline void tsk_restore_flags(struct task_struct *task,
| |
| unsigned long orig_flags, unsigned long flags)
| |
| {
| |
| task->flags &= ~flags;
| |
| task->flags |= orig_flags & flags;
| |
| }
| |
| | |
| #ifdef CONFIG_SMP
| |
| extern void do_set_cpus_allowed(struct task_struct *p,
| |
| const struct cpumask *new_mask);
| |
| | |
| extern int set_cpus_allowed_ptr(struct task_struct *p,
| |
| const struct cpumask *new_mask);
| |
| #else
| |
| static inline void do_set_cpus_allowed(struct task_struct *p,
| |
| const struct cpumask *new_mask)
| |
| {
| |
| }
| |
| static inline int set_cpus_allowed_ptr(struct task_struct *p,
| |
| const struct cpumask *new_mask)
| |
| {
| |
| if (!cpumask_test_cpu(0, new_mask))
| |
| return -EINVAL;
| |
| return 0;
| |
| }
| |
| #endif
| |
| | |
| #ifdef CONFIG_NO_HZ_COMMON
| |
| void calc_load_enter_idle(void);
| |
| void calc_load_exit_idle(void);
| |
| #else
| |
| static inline void calc_load_enter_idle(void) { }
| |
| static inline void calc_load_exit_idle(void) { }
| |
| #endif /* CONFIG_NO_HZ_COMMON */
| |
| | |
| #ifndef CONFIG_CPUMASK_OFFSTACK
| |
| static inline int set_cpus_allowed(struct task_struct *p, cpumask_t new_mask)
| |
| {
| |
| return set_cpus_allowed_ptr(p, &new_mask);
| |
| }
| |
| #endif
| |
| | |
| /*
| |
| * Do not use outside of architecture code which knows its limitations.
| |
| *
| |
| * sched_clock() has no promise of monotonicity or bounded drift between
| |
| * CPUs, use (which you should not) requires disabling IRQs.
| |
| *
| |
| * Please use one of the three interfaces below.
| |
| */
| |
| extern unsigned long long notrace sched_clock(void);
| |
| /*
| |
| * See the comment in kernel/sched/clock.c
| |
| */
| |
| extern u64 cpu_clock(int cpu);
| |
| extern u64 local_clock(void);
| |
| extern u64 sched_clock_cpu(int cpu);
| |
| | |
| | |
| extern void sched_clock_init(void);
| |
| | |
| #ifndef CONFIG_HAVE_UNSTABLE_SCHED_CLOCK
| |
| static inline void sched_clock_tick(void)
| |
| {
| |
| }
| |
| | |
| static inline void sched_clock_idle_sleep_event(void)
| |
| {
| |
| }
| |
| | |
| static inline void sched_clock_idle_wakeup_event(u64 delta_ns)
| |
| {
| |
| }
| |
| #else
| |
| /*
| |
| * Architectures can set this to 1 if they have specified
| |
| * CONFIG_HAVE_UNSTABLE_SCHED_CLOCK in their arch Kconfig,
| |
| * but then during bootup it turns out that sched_clock()
| |
| * is reliable after all:
| |
| */
| |
| extern int sched_clock_stable;
| |
| | |
| extern void sched_clock_tick(void);
| |
| extern void sched_clock_idle_sleep_event(void);
| |
| extern void sched_clock_idle_wakeup_event(u64 delta_ns);
| |
| #endif
| |
| | |
| #ifdef CONFIG_IRQ_TIME_ACCOUNTING
| |
| /*
| |
| * An i/f to runtime opt-in for irq time accounting based off of sched_clock.
| |
| * The reason for this explicit opt-in is not to have perf penalty with
| |
| * slow sched_clocks.
| |
| */
| |
| extern void enable_sched_clock_irqtime(void);
| |
| extern void disable_sched_clock_irqtime(void);
| |
| #else
| |
| static inline void enable_sched_clock_irqtime(void) {}
| |
| static inline void disable_sched_clock_irqtime(void) {}
| |
| #endif
| |
| | |
| extern unsigned long long
| |
| task_sched_runtime(struct task_struct *task);
| |
| | |
| /* sched_exec is called by processes performing an exec */
| |
| #ifdef CONFIG_SMP
| |
| extern void sched_exec(void);
| |
| #else
| |
| #define sched_exec() {}
| |
| #endif
| |
| | |
| extern void sched_clock_idle_sleep_event(void);
| |
| extern void sched_clock_idle_wakeup_event(u64 delta_ns);
| |
| | |
| #ifdef CONFIG_HOTPLUG_CPU
| |
| extern void idle_task_exit(void);
| |
| #else
| |
| static inline void idle_task_exit(void) {}
| |
| #endif
| |
| | |
| #if defined(CONFIG_NO_HZ_COMMON) && defined(CONFIG_SMP)
| |
| extern void wake_up_nohz_cpu(int cpu);
| |
| #else
| |
| static inline void wake_up_nohz_cpu(int cpu) { }
| |
| #endif
| |
| | |
| #ifdef CONFIG_NO_HZ_FULL
| |
| extern bool sched_can_stop_tick(void);
| |
| extern u64 scheduler_tick_max_deferment(void);
| |
| #else
| |
| static inline bool sched_can_stop_tick(void) { return false; }
| |
| #endif
| |
| | |
| #ifdef CONFIG_SCHED_AUTOGROUP
| |
| extern void sched_autogroup_create_attach(struct task_struct *p);
| |
| extern void sched_autogroup_detach(struct task_struct *p);
| |
| extern void sched_autogroup_fork(struct signal_struct *sig);
| |
| extern void sched_autogroup_exit(struct signal_struct *sig);
| |
| #ifdef CONFIG_PROC_FS
| |
| extern void proc_sched_autogroup_show_task(struct task_struct *p, struct seq_file *m);
| |
| extern int proc_sched_autogroup_set_nice(struct task_struct *p, int nice);
| |
| #endif
| |
| #else
| |
| static inline void sched_autogroup_create_attach(struct task_struct *p) { }
| |
| static inline void sched_autogroup_detach(struct task_struct *p) { }
| |
| static inline void sched_autogroup_fork(struct signal_struct *sig) { }
| |
| static inline void sched_autogroup_exit(struct signal_struct *sig) { }
| |
| #endif
| |
| | |
| extern bool yield_to(struct task_struct *p, bool preempt);
| |
| extern void set_user_nice(struct task_struct *p, long nice);
| |
| extern int task_prio(const struct task_struct *p);
| |
| extern int task_nice(const struct task_struct *p);
| |
| extern int can_nice(const struct task_struct *p, const int nice);
| |
| extern int task_curr(const struct task_struct *p);
| |
| extern int idle_cpu(int cpu);
| |
| extern int sched_setscheduler(struct task_struct *, int,
| |
| const struct sched_param *);
| |
| extern int sched_setscheduler_nocheck(struct task_struct *, int,
| |
| const struct sched_param *);
| |
| extern struct task_struct *idle_task(int cpu);
| |
| /**
| |
| * is_idle_task - is the specified task an idle task?
| |
| * @p: the task in question.
| |
| *
| |
| * Return: 1 if @p is an idle task. 0 otherwise.
| |
| */
| |
| static inline bool is_idle_task(const struct task_struct *p)
| |
| {
| |
| return p->pid == 0;
| |
| }
| |
| extern struct task_struct *curr_task(int cpu);
| |
| extern void set_curr_task(int cpu, struct task_struct *p);
| |
| | |
| void yield(void);
| |
| | |
| /*
| |
| * The default (Linux) execution domain.
| |
| */
| |
| extern struct exec_domain default_exec_domain;
| |
| | |
| union thread_union {
| |
| struct thread_info thread_info;
| |
| unsigned long stack[THREAD_SIZE/sizeof(long)];
| |
| };
| |
| | |
| #ifndef __HAVE_ARCH_KSTACK_END
| |
| static inline int kstack_end(void *addr)
| |
| {
| |
| /* Reliable end of stack detection:
| |
| * Some APM bios versions misalign the stack
| |
| */
| |
| return !(((unsigned long)addr+sizeof(void*)-1) & (THREAD_SIZE-sizeof(void*)));
| |
| }
| |
| #endif
| |
| | |
| extern union thread_union init_thread_union;
| |
| extern struct task_struct init_task;
| |
| | |
| extern struct mm_struct init_mm;
| |
| | |
| extern struct pid_namespace init_pid_ns;
| |
| | |
| /*
| |
| * find a task by one of its numerical ids
| |
| *
| |
| * find_task_by_pid_ns():
| |
| * finds a task by its pid in the specified namespace
| |
| * find_task_by_vpid():
| |
| * finds a task by its virtual pid
| |
| *
| |
| * see also find_vpid() etc in include/linux/pid.h
| |
| */
| |
| | |
| extern struct task_struct *find_task_by_vpid(pid_t nr);
| |
| extern struct task_struct *find_task_by_pid_ns(pid_t nr,
| |
| struct pid_namespace *ns);
| |
| | |
| /* per-UID process charging. */
| |
| extern struct user_struct * alloc_uid(kuid_t);
| |
| static inline struct user_struct *get_uid(struct user_struct *u)
| |
| {
| |
| atomic_inc(&u->__count);
| |
| return u;
| |
| }
| |
| extern void free_uid(struct user_struct *);
| |
| | |
| #include <asm/current.h>
| |
| | |
| extern void xtime_update(unsigned long ticks);
| |
| | |
| extern int wake_up_state(struct task_struct *tsk, unsigned int state);
| |
| extern int wake_up_process(struct task_struct *tsk);
| |
| extern void wake_up_new_task(struct task_struct *tsk);
| |
| #ifdef CONFIG_SMP
| |
| extern void kick_process(struct task_struct *tsk);
| |
| #else
| |
| static inline void kick_process(struct task_struct *tsk) { }
| |
| #endif
| |
| extern void sched_fork(unsigned long clone_flags, struct task_struct *p);
| |
| extern void sched_dead(struct task_struct *p);
| |
| | |
| extern void proc_caches_init(void);
| |
| extern void flush_signals(struct task_struct *);
| |
| extern void __flush_signals(struct task_struct *);
| |
| extern void ignore_signals(struct task_struct *);
| |
| extern void flush_signal_handlers(struct task_struct *, int force_default);
| |
| extern int dequeue_signal(struct task_struct *tsk, sigset_t *mask, siginfo_t *info);
| |
| | |
| static inline int dequeue_signal_lock(struct task_struct *tsk, sigset_t *mask, siginfo_t *info)
| |
| {
| |
| unsigned long flags;
| |
| int ret;
| |
| | |
| spin_lock_irqsave(&tsk->sighand->siglock, flags);
| |
| ret = dequeue_signal(tsk, mask, info);
| |
| spin_unlock_irqrestore(&tsk->sighand->siglock, flags);
| |
| | |
| return ret;
| |
| }
| |
| | |
| extern void block_all_signals(int (*notifier)(void *priv), void *priv,
| |
| sigset_t *mask);
| |
| extern void unblock_all_signals(void);
| |
| extern void release_task(struct task_struct * p);
| |
| extern int send_sig_info(int, struct siginfo *, struct task_struct *);
| |
| extern int force_sigsegv(int, struct task_struct *);
| |
| extern int force_sig_info(int, struct siginfo *, struct task_struct *);
| |
| extern int __kill_pgrp_info(int sig, struct siginfo *info, struct pid *pgrp);
| |
| extern int kill_pid_info(int sig, struct siginfo *info, struct pid *pid);
| |
| extern int kill_pid_info_as_cred(int, struct siginfo *, struct pid *,
| |
| const struct cred *, u32);
| |
| extern int kill_pgrp(struct pid *pid, int sig, int priv);
| |
| extern int kill_pid(struct pid *pid, int sig, int priv);
| |
| extern int kill_proc_info(int, struct siginfo *, pid_t);
| |
| extern __must_check bool do_notify_parent(struct task_struct *, int);
| |
| extern void __wake_up_parent(struct task_struct *p, struct task_struct *parent);
| |
| extern void force_sig(int, struct task_struct *);
| |
| extern int send_sig(int, struct task_struct *, int);
| |
| extern int zap_other_threads(struct task_struct *p);
| |
| extern struct sigqueue *sigqueue_alloc(void);
| |
| extern void sigqueue_free(struct sigqueue *);
| |
| extern int send_sigqueue(struct sigqueue *, struct task_struct *, int group);
| |
| extern int do_sigaction(int, struct k_sigaction *, struct k_sigaction *);
| |
| | |
| static inline void restore_saved_sigmask(void)
| |
| {
| |
| if (test_and_clear_restore_sigmask())
| |
| __set_current_blocked(¤t->saved_sigmask);
| |
| }
| |
| | |
| static inline sigset_t *sigmask_to_save(void)
| |
| {
| |
| sigset_t *res = ¤t->blocked;
| |
| if (unlikely(test_restore_sigmask()))
| |
| res = ¤t->saved_sigmask;
| |
| return res;
| |
| }
| |
| | |
| static inline int kill_cad_pid(int sig, int priv)
| |
| {
| |
| return kill_pid(cad_pid, sig, priv);
| |
| }
| |
| | |
| /* These can be the second arg to send_sig_info/send_group_sig_info. */
| |
| #define SEND_SIG_NOINFO ((struct siginfo *) 0)
| |
| #define SEND_SIG_PRIV ((struct siginfo *) 1)
| |
| #define SEND_SIG_FORCED ((struct siginfo *) 2)
| |
| | |
| /*
| |
| * True if we are on the alternate signal stack.
| |
| */
| |
| static inline int on_sig_stack(unsigned long sp)
| |
| {
| |
| #ifdef CONFIG_STACK_GROWSUP
| |
| return sp >= current->sas_ss_sp &&
| |
| sp - current->sas_ss_sp < current->sas_ss_size;
| |
| #else
| |
| return sp > current->sas_ss_sp &&
| |
| sp - current->sas_ss_sp <= current->sas_ss_size;
| |
| #endif
| |
| }
| |
| | |
| static inline int sas_ss_flags(unsigned long sp)
| |
| {
| |
| return (current->sas_ss_size == 0 ? SS_DISABLE
| |
| : on_sig_stack(sp) ? SS_ONSTACK : 0);
| |
| }
| |
| | |
| static inline unsigned long sigsp(unsigned long sp, struct ksignal *ksig)
| |
| {
| |
| if (unlikely((ksig->ka.sa.sa_flags & SA_ONSTACK)) && ! sas_ss_flags(sp))
| |
| #ifdef CONFIG_STACK_GROWSUP
| |
| return current->sas_ss_sp;
| |
| #else
| |
| return current->sas_ss_sp + current->sas_ss_size;
| |
| #endif
| |
| return sp;
| |
| }
| |
| | |
| /*
| |
| * Routines for handling mm_structs
| |
| */
| |
| extern struct mm_struct * mm_alloc(void);
| |
| | |
| /* mmdrop drops the mm and the page tables */
| |
| extern void __mmdrop(struct mm_struct *);
| |
| static inline void mmdrop(struct mm_struct * mm)
| |
| {
| |
| if (unlikely(atomic_dec_and_test(&mm->mm_count)))
| |
| __mmdrop(mm);
| |
| }
| |
| | |
| /* mmput gets rid of the mappings and all user-space */
| |
| extern void mmput(struct mm_struct *);
| |
| /* Grab a reference to a task's mm, if it is not already going away */
| |
| extern struct mm_struct *get_task_mm(struct task_struct *task);
| |
| /*
| |
| * Grab a reference to a task's mm, if it is not already going away
| |
| * and ptrace_may_access with the mode parameter passed to it
| |
| * succeeds.
| |
| */
| |
| extern struct mm_struct *mm_access(struct task_struct *task, unsigned int mode);
| |
| /* Remove the current tasks stale references to the old mm_struct */
| |
| extern void mm_release(struct task_struct *, struct mm_struct *);
| |
| /* Allocate a new mm structure and copy contents from tsk->mm */
| |
| extern struct mm_struct *dup_mm(struct task_struct *tsk);
| |
| | |
| extern int copy_thread(unsigned long, unsigned long, unsigned long,
| |
| struct task_struct *);
| |
| extern void flush_thread(void);
| |
| extern void exit_thread(void);
| |
| | |
| extern void exit_files(struct task_struct *);
| |
| extern void __cleanup_sighand(struct sighand_struct *);
| |
| | |
| extern void exit_itimers(struct signal_struct *);
| |
| extern void flush_itimer_signals(void);
| |
| | |
| extern void do_group_exit(int);
| |
| | |
| extern int allow_signal(int);
| |
| extern int disallow_signal(int);
| |
| | |
| extern int do_execve(const char *,
| |
| const char __user * const __user *,
| |
| const char __user * const __user *);
| |
| extern long do_fork(unsigned long, unsigned long, unsigned long, int __user *, int __user *);
| |
| struct task_struct *fork_idle(int);
| |
| extern pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags);
| |
| | |
| extern void set_task_comm(struct task_struct *tsk, char *from);
| |
| extern char *get_task_comm(char *to, struct task_struct *tsk);
| |
| | |
| #ifdef CONFIG_SMP
| |
| void scheduler_ipi(void);
| |
| extern unsigned long wait_task_inactive(struct task_struct *, long match_state);
| |
| #else
| |
| static inline void scheduler_ipi(void) { }
| |
| static inline unsigned long wait_task_inactive(struct task_struct *p,
| |
| long match_state)
| |
| {
| |
| return 1;
| |
| }
| |
| #endif
| |
| | |
| #define next_task(p) \
| |
| list_entry_rcu((p)->tasks.next, struct task_struct, tasks)
| |
| | |
| #define for_each_process(p) \
| |
| for (p = &init_task ; (p = next_task(p)) != &init_task ; )
| |
| | |
| extern bool current_is_single_threaded(void);
| |
| | |
| /*
| |
| * Careful: do_each_thread/while_each_thread is a double loop so
| |
| * 'break' will not work as expected - use goto instead.
| |
| */
| |
| #define do_each_thread(g, t) \
| |
| for (g = t = &init_task ; (g = t = next_task(g)) != &init_task ; ) do
| |
| | |
| #define while_each_thread(g, t) \
| |
| while ((t = next_thread(t)) != g)
| |
| | |
| #define __for_each_thread(signal, t) \
| |
| list_for_each_entry_rcu(t, &(signal)->thread_head, thread_node)
| |
| | |
| #define for_each_thread(p, t) \
| |
| __for_each_thread((p)->signal, t)
| |
| | |
| /* Careful: this is a double loop, 'break' won't work as expected. */
| |
| #define for_each_process_thread(p, t) \
| |
| for_each_process(p) for_each_thread(p, t)
| |
| | |
| static inline int get_nr_threads(struct task_struct *tsk)
| |
| {
| |
| return tsk->signal->nr_threads;
| |
| }
| |
| | |
| static inline bool thread_group_leader(struct task_struct *p)
| |
| {
| |
| return p->exit_signal >= 0;
| |
| }
| |
| | |
| /* Do to the insanities of de_thread it is possible for a process
| |
| * to have the pid of the thread group leader without actually being
| |
| * the thread group leader. For iteration through the pids in proc
| |
| * all we care about is that we have a task with the appropriate
| |
| * pid, we don't actually care if we have the right task.
| |
| */
| |
| static inline bool has_group_leader_pid(struct task_struct *p)
| |
| {
| |
| return task_pid(p) == p->signal->leader_pid;
| |
| }
| |
| | |
| static inline
| |
| bool same_thread_group(struct task_struct *p1, struct task_struct *p2)
| |
| {
| |
| return p1->signal == p2->signal;
| |
| }
| |
| | |
| static inline struct task_struct *next_thread(const struct task_struct *p)
| |
| {
| |
| return list_entry_rcu(p->thread_group.next,
| |
| struct task_struct, thread_group);
| |
| }
| |
| | |
| static inline int thread_group_empty(struct task_struct *p)
| |
| {
| |
| return list_empty(&p->thread_group);
| |
| }
| |
| | |
| #define delay_group_leader(p) \
| |
| (thread_group_leader(p) && !thread_group_empty(p))
| |
| | |
| /*
| |
| * Protects ->fs, ->files, ->mm, ->group_info, ->comm, keyring
| |
| * subscriptions and synchronises with wait4(). Also used in procfs. Also
| |
| * pins the final release of task.io_context. Also protects ->cpuset and
| |
| * ->cgroup.subsys[]. And ->vfork_done.
| |
| *
| |
| * Nests both inside and outside of read_lock(&tasklist_lock).
| |
| * It must not be nested with write_lock_irq(&tasklist_lock),
| |
| * neither inside nor outside.
| |
| */
| |
| static inline void task_lock(struct task_struct *p)
| |
| {
| |
| spin_lock(&p->alloc_lock);
| |
| }
| |
| | |
| static inline void task_unlock(struct task_struct *p)
| |
| {
| |
| spin_unlock(&p->alloc_lock);
| |
| }
| |
| | |
| extern struct sighand_struct *__lock_task_sighand(struct task_struct *tsk,
| |
| unsigned long *flags);
| |
| | |
| static inline struct sighand_struct *lock_task_sighand(struct task_struct *tsk,
| |
| unsigned long *flags)
| |
| {
| |
| struct sighand_struct *ret;
| |
| | |
| ret = __lock_task_sighand(tsk, flags);
| |
| (void)__cond_lock(&tsk->sighand->siglock, ret);
| |
| return ret;
| |
| }
| |
| | |
| static inline void unlock_task_sighand(struct task_struct *tsk,
| |
| unsigned long *flags)
| |
| {
| |
| spin_unlock_irqrestore(&tsk->sighand->siglock, *flags);
| |
| }
| |
| | |
| #ifdef CONFIG_CGROUPS | |
| static inline void threadgroup_change_begin(struct task_struct *tsk)
| |
| {
| |
| down_read(&tsk->signal->group_rwsem);
| |
| }
| |
| static inline void threadgroup_change_end(struct task_struct *tsk)
| |
| {
| |
| up_read(&tsk->signal->group_rwsem);
| |
| }
| |
| | |
| /**
| |
| * threadgroup_lock - lock threadgroup
| |
| * @tsk: member task of the threadgroup to lock
| |
| *
| |
| * Lock the threadgroup @tsk belongs to. No new task is allowed to enter
| |
| * and member tasks aren't allowed to exit (as indicated by PF_EXITING) or
| |
| * change ->group_leader/pid. This is useful for cases where the threadgroup
| |
| * needs to stay stable across blockable operations.
| |
| *
| |
| * fork and exit paths explicitly call threadgroup_change_{begin|end}() for
| |
| * synchronization. While held, no new task will be added to threadgroup
| |
| * and no existing live task will have its PF_EXITING set.
| |
| *
| |
| * de_thread() does threadgroup_change_{begin|end}() when a non-leader
| |
| * sub-thread becomes a new leader.
| |
| */
| |
| static inline void threadgroup_lock(struct task_struct *tsk)
| |
| {
| |
| down_write(&tsk->signal->group_rwsem);
| |
| }
| |
| | |
| /**
| |
| * threadgroup_unlock - unlock threadgroup
| |
| * @tsk: member task of the threadgroup to unlock
| |
| *
| |
| * Reverse threadgroup_lock().
| |
| */
| |
| static inline void threadgroup_unlock(struct task_struct *tsk)
| |
| {
| |
| up_write(&tsk->signal->group_rwsem);
| |
| }
| |
| #else
| |
| static inline void threadgroup_change_begin(struct task_struct *tsk) {}
| |
| static inline void threadgroup_change_end(struct task_struct *tsk) {}
| |
| static inline void threadgroup_lock(struct task_struct *tsk) {}
| |
| static inline void threadgroup_unlock(struct task_struct *tsk) {}
| |
| #endif
| |
| | |
| #ifndef __HAVE_THREAD_FUNCTIONS
| |
| | |
| #define task_thread_info(task) ((struct thread_info *)(task)->stack)
| |
| #define task_stack_page(task) ((task)->stack)
| |
| | |
| static inline void setup_thread_stack(struct task_struct *p, struct task_struct *org)
| |
| {
| |
| *task_thread_info(p) = *task_thread_info(org);
| |
| task_thread_info(p)->task = p;
| |
| }
| |
| | |
| static inline unsigned long *end_of_stack(struct task_struct *p)
| |
| {
| |
| return (unsigned long *)(task_thread_info(p) + 1);
| |
| }
| |
| | |
| #endif
| |
| | |
| static inline int object_is_on_stack(void *obj)
| |
| {
| |
| void *stack = task_stack_page(current);
| |
| | |
| return (obj >= stack) && (obj < (stack + THREAD_SIZE));
| |
| }
| |
| | |
| extern void thread_info_cache_init(void);
| |
| | |
| #ifdef CONFIG_DEBUG_STACK_USAGE
| |
| static inline unsigned long stack_not_used(struct task_struct *p)
| |
| {
| |
| unsigned long *n = end_of_stack(p);
| |
| | |
| do { /* Skip over canary */
| |
| n++;
| |
| } while (!*n);
| |
| | |
| return (unsigned long)n - (unsigned long)end_of_stack(p);
| |
| }
| |
| #endif
| |
| | |
| /* set thread flags in other task's structures
| |
| * - see asm/thread_info.h for TIF_xxxx flags available
| |
| */
| |
| static inline void set_tsk_thread_flag(struct task_struct *tsk, int flag)
| |
| {
| |
| set_ti_thread_flag(task_thread_info(tsk), flag);
| |
| }
| |
| | |
| static inline void clear_tsk_thread_flag(struct task_struct *tsk, int flag)
| |
| {
| |
| clear_ti_thread_flag(task_thread_info(tsk), flag);
| |
| }
| |
| | |
| static inline int test_and_set_tsk_thread_flag(struct task_struct *tsk, int flag)
| |
| {
| |
| return test_and_set_ti_thread_flag(task_thread_info(tsk), flag);
| |
| }
| |
| | |
| static inline int test_and_clear_tsk_thread_flag(struct task_struct *tsk, int flag)
| |
| {
| |
| return test_and_clear_ti_thread_flag(task_thread_info(tsk), flag);
| |
| }
| |
| | |
| static inline int test_tsk_thread_flag(struct task_struct *tsk, int flag)
| |
| {
| |
| return test_ti_thread_flag(task_thread_info(tsk), flag);
| |
| }
| |
| | |
| static inline void set_tsk_need_resched(struct task_struct *tsk)
| |
| {
| |
| set_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
| |
| }
| |
| | |
| static inline void clear_tsk_need_resched(struct task_struct *tsk)
| |
| {
| |
| clear_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
| |
| }
| |
| | |
| static inline int test_tsk_need_resched(struct task_struct *tsk)
| |
| {
| |
| return unlikely(test_tsk_thread_flag(tsk,TIF_NEED_RESCHED));
| |
| }
| |
| | |
| static inline int restart_syscall(void)
| |
| {
| |
| set_tsk_thread_flag(current, TIF_SIGPENDING);
| |
| return -ERESTARTNOINTR;
| |
| }
| |
| | |
| static inline int signal_pending(struct task_struct *p)
| |
| {
| |
| return unlikely(test_tsk_thread_flag(p,TIF_SIGPENDING));
| |
| }
| |
| | |
| static inline int __fatal_signal_pending(struct task_struct *p)
| |
| {
| |
| return unlikely(sigismember(&p->pending.signal, SIGKILL));
| |
| }
| |
| | |
| static inline int fatal_signal_pending(struct task_struct *p)
| |
| {
| |
| return signal_pending(p) && __fatal_signal_pending(p);
| |
| }
| |
| | |
| static inline int signal_pending_state(long state, struct task_struct *p)
| |
| {
| |
| if (!(state & (TASK_INTERRUPTIBLE | TASK_WAKEKILL)))
| |
| return 0;
| |
| if (!signal_pending(p))
| |
| return 0;
| |
| | |
| return (state & TASK_INTERRUPTIBLE) || __fatal_signal_pending(p);
| |
| }
| |
| | |
| /*
| |
| * cond_resched() and cond_resched_lock(): latency reduction via
| |
| * explicit rescheduling in places that are safe. The return
| |
| * value indicates whether a reschedule was done in fact.
| |
| * cond_resched_lock() will drop the spinlock before scheduling,
| |
| * cond_resched_softirq() will enable bhs before scheduling.
| |
| */
| |
| extern int _cond_resched(void);
| |
| | |
| #define cond_resched() ({ \
| |
| __might_sleep(__FILE__, __LINE__, 0); \
| |
| _cond_resched(); \
| |
| })
| |
| | |
| extern int __cond_resched_lock(spinlock_t *lock);
| |
| | |
| #ifdef CONFIG_PREEMPT_COUNT
| |
| #define PREEMPT_LOCK_OFFSET PREEMPT_OFFSET
| |
| #else
| |
| #define PREEMPT_LOCK_OFFSET 0
| |
| #endif
| |
| | |
| #define cond_resched_lock(lock) ({ \
| |
| __might_sleep(__FILE__, __LINE__, PREEMPT_LOCK_OFFSET); \
| |
| __cond_resched_lock(lock); \
| |
| })
| |
| | |
| extern int __cond_resched_softirq(void);
| |
| | |
| #define cond_resched_softirq() ({ \
| |
| __might_sleep(__FILE__, __LINE__, SOFTIRQ_DISABLE_OFFSET); \
| |
| __cond_resched_softirq(); \
| |
| })
| |
| | |
| static inline void cond_resched_rcu(void)
| |
| {
| |
| #if defined(CONFIG_DEBUG_ATOMIC_SLEEP) || !defined(CONFIG_PREEMPT_RCU)
| |
| rcu_read_unlock();
| |
| cond_resched();
| |
| rcu_read_lock();
| |
| #endif
| |
| }
| |
| | |
| /*
| |
| * Does a critical section need to be broken due to another
| |
| * task waiting?: (technically does not depend on CONFIG_PREEMPT,
| |
| * but a general need for low latency)
| |
| */
| |
| static inline int spin_needbreak(spinlock_t *lock)
| |
| {
| |
| #ifdef CONFIG_PREEMPT
| |
| return spin_is_contended(lock);
| |
| #else
| |
| return 0;
| |
| #endif
| |
| }
| |
| | |
| /*
| |
| * Idle thread specific functions to determine the need_resched
| |
| * polling state. We have two versions, one based on TS_POLLING in
| |
| * thread_info.status and one based on TIF_POLLING_NRFLAG in
| |
| * thread_info.flags
| |
| */
| |
| #ifdef TS_POLLING
| |
| static inline int tsk_is_polling(struct task_struct *p)
| |
| {
| |
| return task_thread_info(p)->status & TS_POLLING;
| |
| }
| |
| static inline void __current_set_polling(void)
| |
| {
| |
| current_thread_info()->status |= TS_POLLING;
| |
| }
| |
| | |
| static inline bool __must_check current_set_polling_and_test(void)
| |
| {
| |
| __current_set_polling();
| |
| | |
| /*
| |
| * Polling state must be visible before we test NEED_RESCHED,
| |
| * paired by resched_task()
| |
| */
| |
| smp_mb();
| |
| | |
| return unlikely(tif_need_resched());
| |
| }
| |
| | |
| static inline void __current_clr_polling(void)
| |
| {
| |
| current_thread_info()->status &= ~TS_POLLING;
| |
| }
| |
| | |
| static inline bool __must_check current_clr_polling_and_test(void)
| |
| {
| |
| __current_clr_polling();
| |
| | |
| /*
| |
| * Polling state must be visible before we test NEED_RESCHED,
| |
| * paired by resched_task()
| |
| */
| |
| smp_mb();
| |
| | |
| return unlikely(tif_need_resched());
| |
| }
| |
| #elif defined(TIF_POLLING_NRFLAG)
| |
| static inline int tsk_is_polling(struct task_struct *p)
| |
| {
| |
| return test_tsk_thread_flag(p, TIF_POLLING_NRFLAG);
| |
| }
| |
| | |
| static inline void __current_set_polling(void)
| |
| {
| |
| set_thread_flag(TIF_POLLING_NRFLAG);
| |
| }
| |
| | |
| static inline bool __must_check current_set_polling_and_test(void)
| |
| {
| |
| __current_set_polling();
| |
| | |
| /*
| |
| * Polling state must be visible before we test NEED_RESCHED,
| |
| * paired by resched_task()
| |
| *
| |
| * XXX: assumes set/clear bit are identical barrier wise.
| |
| */
| |
| smp_mb__after_clear_bit();
| |
| | |
| return unlikely(tif_need_resched());
| |
| }
| |
| | |
| static inline void __current_clr_polling(void)
| |
| {
| |
| clear_thread_flag(TIF_POLLING_NRFLAG);
| |
| }
| |
| | |
| static inline bool __must_check current_clr_polling_and_test(void)
| |
| {
| |
| __current_clr_polling();
| |
| | |
| /*
| |
| * Polling state must be visible before we test NEED_RESCHED,
| |
| * paired by resched_task()
| |
| */
| |
| smp_mb__after_clear_bit();
| |
| | |
| return unlikely(tif_need_resched());
| |
| }
| |
| | |
| #else
| |
| static inline int tsk_is_polling(struct task_struct *p) { return 0; }
| |
| static inline void __current_set_polling(void) { }
| |
| static inline void __current_clr_polling(void) { }
| |
| | |
| static inline bool __must_check current_set_polling_and_test(void)
| |
| {
| |
| return unlikely(tif_need_resched());
| |
| }
| |
| static inline bool __must_check current_clr_polling_and_test(void)
| |
| {
| |
| return unlikely(tif_need_resched());
| |
| }
| |
| #endif
| |
| | |
| static __always_inline bool need_resched(void)
| |
| {
| |
| return unlikely(tif_need_resched());
| |
| }
| |
| | |
| /*
| |
| * Thread group CPU time accounting.
| |
| */
| |
| void thread_group_cputime(struct task_struct *tsk, struct task_cputime *times);
| |
| void thread_group_cputimer(struct task_struct *tsk, struct task_cputime *times);
| |
| | |
| static inline void thread_group_cputime_init(struct signal_struct *sig)
| |
| {
| |
| raw_spin_lock_init(&sig->cputimer.lock);
| |
| }
| |
| | |
| /*
| |
| * Reevaluate whether the task has signals pending delivery.
| |
| * Wake the task if so.
| |
| * This is required every time the blocked sigset_t changes.
| |
| * callers must hold sighand->siglock.
| |
| */
| |
| extern void recalc_sigpending_and_wake(struct task_struct *t);
| |
| extern void recalc_sigpending(void);
| |
| | |
| extern void signal_wake_up_state(struct task_struct *t, unsigned int state);
| |
| | |
| static inline void signal_wake_up(struct task_struct *t, bool resume)
| |
| {
| |
| signal_wake_up_state(t, resume ? TASK_WAKEKILL : 0);
| |
| }
| |
| static inline void ptrace_signal_wake_up(struct task_struct *t, bool resume)
| |
| {
| |
| signal_wake_up_state(t, resume ? __TASK_TRACED : 0);
| |
| }
| |
| | |
| /*
| |
| * Wrappers for p->thread_info->cpu access. No-op on UP.
| |
| */
| |
| #ifdef CONFIG_SMP
| |
| | |
| static inline unsigned int task_cpu(const struct task_struct *p)
| |
| {
| |
| return task_thread_info(p)->cpu;
| |
| }
| |
| | |
| static inline int task_node(const struct task_struct *p)
| |
| {
| |
| return cpu_to_node(task_cpu(p));
| |
| }
| |
| | |
| extern void set_task_cpu(struct task_struct *p, unsigned int cpu);
| |
| | |
| #else
| |
| | |
| static inline unsigned int task_cpu(const struct task_struct *p)
| |
| {
| |
| return 0;
| |
| }
| |
| | |
| static inline void set_task_cpu(struct task_struct *p, unsigned int cpu)
| |
| {
| |
| }
| |
| | |
| #endif /* CONFIG_SMP */
| |
| | |
| extern long sched_setaffinity(pid_t pid, const struct cpumask *new_mask);
| |
| extern long sched_getaffinity(pid_t pid, struct cpumask *mask);
| |
| | |
| #ifdef CONFIG_CGROUP_SCHED
| |
| extern struct task_group root_task_group;
| |
| #endif /* CONFIG_CGROUP_SCHED */
| |
| | |
| extern int task_can_switch_user(struct user_struct *up,
| |
| struct task_struct *tsk);
| |
| | |
| #ifdef CONFIG_TASK_XACCT
| |
| static inline void add_rchar(struct task_struct *tsk, ssize_t amt)
| |
| {
| |
| tsk->ioac.rchar += amt;
| |
| }
| |
| | |
| static inline void add_wchar(struct task_struct *tsk, ssize_t amt)
| |
| {
| |
| tsk->ioac.wchar += amt;
| |
| }
| |
| | |
| static inline void inc_syscr(struct task_struct *tsk)
| |
| {
| |
| tsk->ioac.syscr++;
| |
| }
| |
| | |
| static inline void inc_syscw(struct task_struct *tsk)
| |
| {
| |
| tsk->ioac.syscw++;
| |
| }
| |
| #else
| |
| static inline void add_rchar(struct task_struct *tsk, ssize_t amt)
| |
| {
| |
| }
| |
| | |
| static inline void add_wchar(struct task_struct *tsk, ssize_t amt)
| |
| {
| |
| }
| |
| | |
| static inline void inc_syscr(struct task_struct *tsk)
| |
| {
| |
| }
| |
| | |
| static inline void inc_syscw(struct task_struct *tsk)
| |
| {
| |
| }
| |
| #endif
| |
| | |
| #ifndef TASK_SIZE_OF
| |
| #define TASK_SIZE_OF(tsk) TASK_SIZE
| |
| #endif
| |
| | |
| #ifdef CONFIG_MM_OWNER
| |
| extern void mm_update_next_owner(struct mm_struct *mm);
| |
| extern void mm_init_owner(struct mm_struct *mm, struct task_struct *p);
| |
| #else
| |
| static inline void mm_update_next_owner(struct mm_struct *mm)
| |
| {
| |
| }
| |
| | |
| static inline void mm_init_owner(struct mm_struct *mm, struct task_struct *p)
| |
| {
| |
| }
| |
| #endif /* CONFIG_MM_OWNER */
| |
| | |
| static inline unsigned long task_rlimit(const struct task_struct *tsk,
| |
| unsigned int limit)
| |
| {
| |
| return ACCESS_ONCE(tsk->signal->rlim[limit].rlim_cur);
| |
| }
| |
| | |
| static inline unsigned long task_rlimit_max(const struct task_struct *tsk,
| |
| unsigned int limit)
| |
| {
| |
| return ACCESS_ONCE(tsk->signal->rlim[limit].rlim_max);
| |
| }
| |
| | |
| static inline unsigned long rlimit(unsigned int limit)
| |
| {
| |
| return task_rlimit(current, limit);
| |
| }
| |
| | |
| static inline unsigned long rlimit_max(unsigned int limit)
| |
| {
| |
| return task_rlimit_max(current, limit);
| |
| }
| |
| | |
| #endif
| |
| </source>
| |
| </loop_listing> | |
| </p> | | </p> |
|
| |
|
| Zeile 2.842: |
Zeile 493: |
| <sub>Diese Seite steht unter der [http://creativecommons.org/licenses/by/3.0/deed.de Creative Commons Namensnennung 3.0 Unported Lizenz] [http://creativecommons.org/licenses/by/3.0/deed.de http://i.creativecommons.org/l/by/3.0/80x15.png] | | <sub>Diese Seite steht unter der [http://creativecommons.org/licenses/by/3.0/deed.de Creative Commons Namensnennung 3.0 Unported Lizenz] [http://creativecommons.org/licenses/by/3.0/deed.de http://i.creativecommons.org/l/by/3.0/80x15.png] |
| </sub> | | </sub> |
| | |
| | <br /> |